0x01 背景
前两天遇到一个解码的问题觉得比较有意思,记录下;
之前对这个方面都没关注过,但是个人觉得这个是一个非常强大的软技能,梳理清楚之后可以提高个人对数据的敏感度。
当时待解码的内容如下:
1
PayLoad(1135)=0b21JZD0ma253bGdEZXRhaWw9JTdCJTIyc2VhcmNoVGl0bGVUeXBlTm0lMjIlM0ElMjIlRTUlODUlQTglRTYlOTYlODclRTYlOTAlOUMlRTclQjQlQTIlMjIlMkMlMjJrbndsZ05tJTIyJTNBJTIyJUU5IiwiJHRpdGxlIjoi6ZqP5b%2BD55yL5Lya5ZGY77yI5Zub5bed77yJIiwiJHVybF9wYXRoIjoiL3ByZC1uZ2ttL29zcy8yMjA3MTIxNTE2NDQwMTEzMjY2XzI4MC5odG1sIiwiZXZlbnRfZHVyYXRpb24iOjg1MS42MDIsIiRsYXRlc3RfcmVmZXJyZXIiOiLlj5blgLzlvILluLgiLCIkbGF0ZXN0X3NlYXJjaF9rZXl3b3JkIjoi5Y%2BW5YC85byC5bi4IiwiJGxhdGVzdF90cmFmZmljX3NvdXJjZV90eXBlIjoi5Y%2BW5YC85byC5bi4IiwiJGlzX2ZpcnN0X2RheSI6dHJ1ZX0sImFub255bW91c19pZCI6Ik9QNzAxNzI4IiwidHlwZSI6InRyYWNrIiwiZXZlbnQiOiIkV2ViU3RheSIsIl90cmFja19pZCI6Njc5NDU0MzAyfQ%3D%3D&ext=crc%3D-975497887 HTTP/1.1\0d\0aHost: xxx.xxx.xxx\0d\0aProxy-Connection: keep-alive\0d\0aCache-Control: max-age=0\0d\0aUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36\0d\0aAccept: */*\0d\0aReferer: http://ngkm.cs.cmos/prd-ngkm/oss/2207121516440113266_280.html?AWSAccessKeyId=xxxxxxx&Expires=41006;
简单看,这个因该是一个http的的请求流量,可以看到下面部门的内容被url编码了,解码看下:
1
0b21JZD0ma253bGdEZXRhaWw9JTdCJTIyc2VhcmNoVGl0bGVUeXBlTm0lMjIlM0ElMjIlRTUlODUlQTglRTYlOTYlODclRTYlOTAlOUMlRTclQjQlQTIlMjIlMkMlMjJrbndsZ05tJTIyJTNBJTIyJUU5IiwiJHRpdGxlIjoi6ZqP5b%2BD55yL5Lya5ZGY77yI5Zub5bed77yJIiwiJHVybF9wYXRoIjoiL3ByZC1uZ2ttL29zcy8yMjA3MTIxNTE2NDQwMTEzMjY2XzI4MC5odG1sIiwiZXZlbnRfZHVyYXRpb24iOjg1MS42MDIsIiRsYXRlc3RfcmVmZXJyZXIiOiLlj5blgLzlvILluLgiLCIkbGF0ZXN0X3NlYXJjaF9rZXl3b3JkIjoi5Y%2BW5YC85byC5bi4IiwiJGxhdGVzdF90cmFmZmljX3NvdXJjZV90eXBlIjoi5Y%2BW5YC85byC5bi4IiwiJGlzX2ZpcnN0X2RheSI6dHJ1ZX0sImFub255bW91c19pZCI6Ik9QNzAxNzI4IiwidHlwZSI6InRyYWNrIiwiZXZlbnQiOiIkV2ViU3RheSIsIl90cmFja19pZCI6Njc5NDU0MzAyfQ%3D%3D
url解码后:
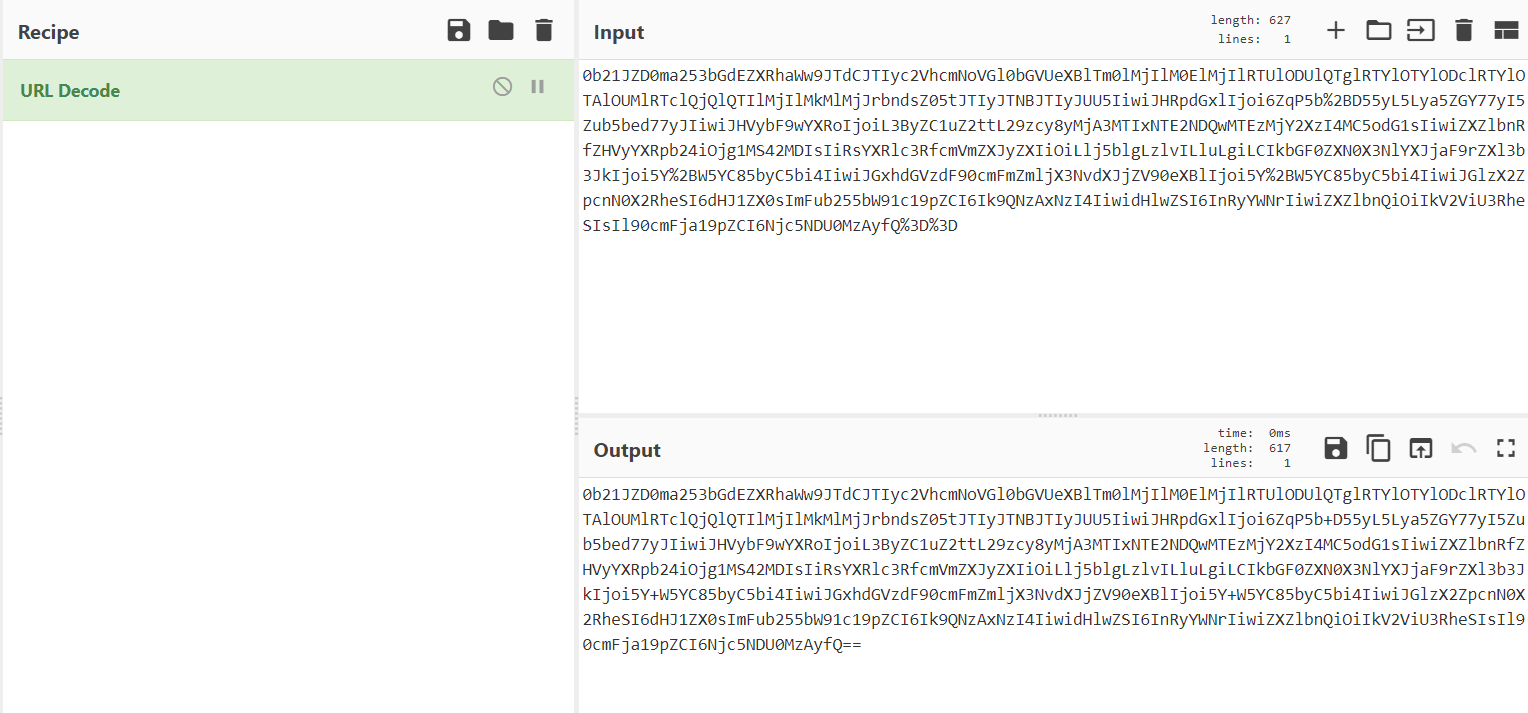
这个结果一看,就是base64,每个字符都在[A-Za-z0-9+/=]里面,并且结尾存在“=” 填充;
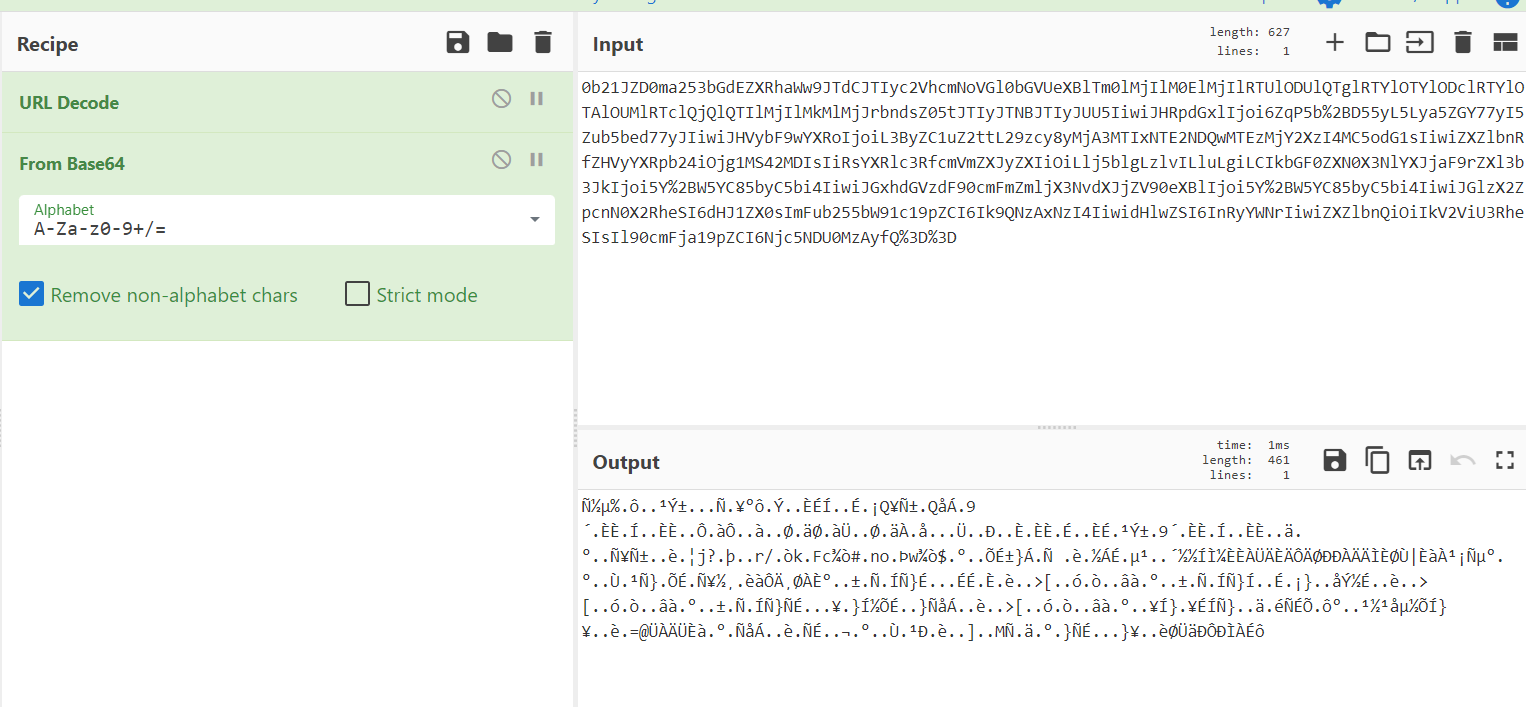
尝试base64解码:如下图,解出来是乱码
转成hex:如下图:
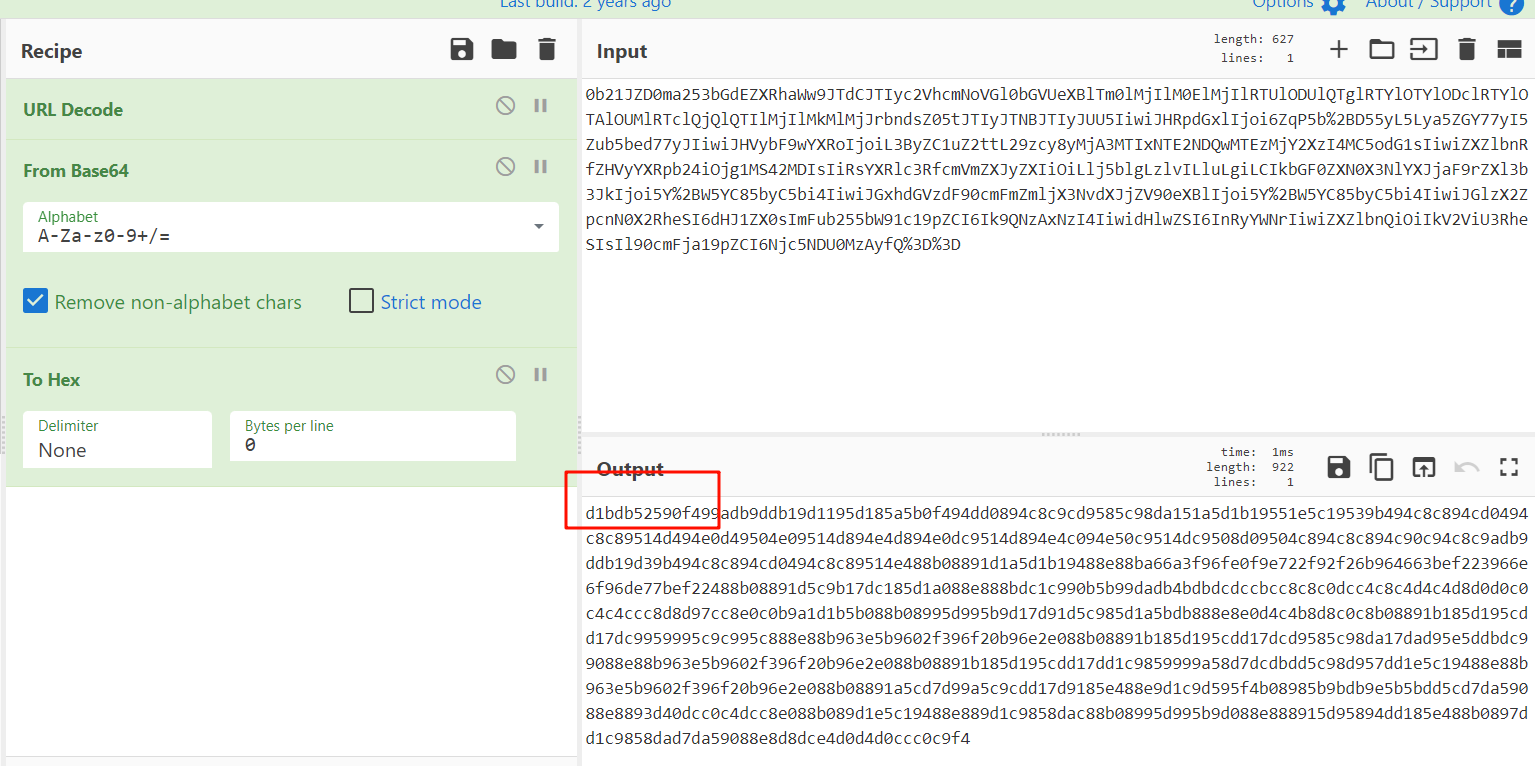
根据前面几位也没看出来是什么特殊格式;
至此,我推断这个东西是一个加密之后的内容,常见的比如aes、des之类的,使用填充选择nopadding的确可能出现这种长度的内容;
那天正好openai 宣布gpt4可以免费使用了,于是抱着玩一玩的心态一个同事把这个丢给gpt,看看能解出来不;
结果如下,还真就解出来了一些,并且格式也正确(这里有个细节:后面核对发现,英文和格式都出来了,但是中文还原都是有问题的):
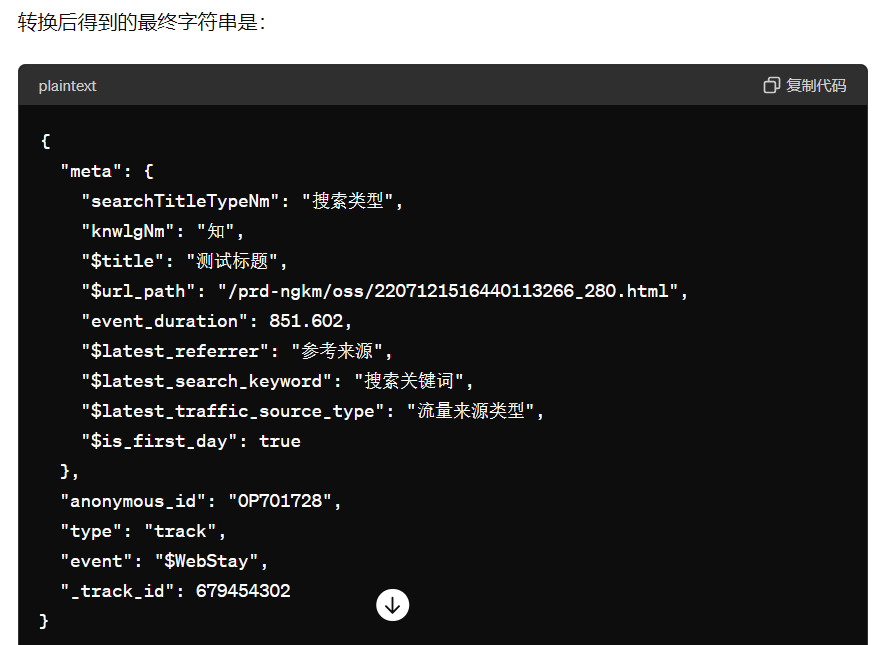
都知道ai的“尿性”,有时候喜欢望文生义,胡说八道,所以这里我们进行了多次尝试,反复开新token问ai,结果给出的回答都是这个,这说明,这次这个还真不是ai乱来;
然后我们让ai给出详细的解码过程,如下图,ai 在解码过程中莫名奇妙的把 最前面的那个0去了:
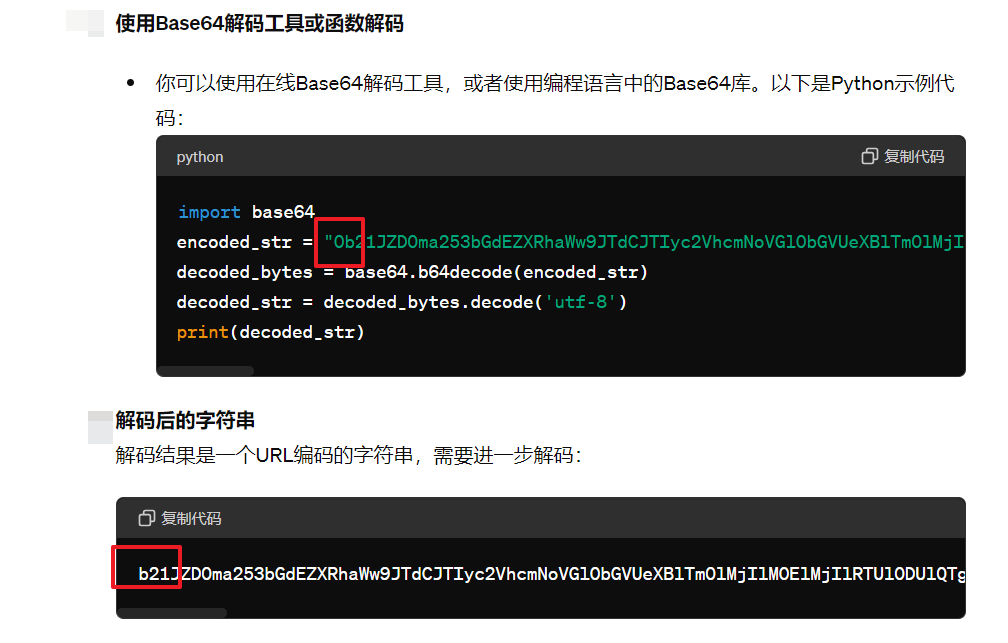
于是我们尝试了下,去除第一个0,然后base64解码:结果如下,”wc”这也行;太离谱了;
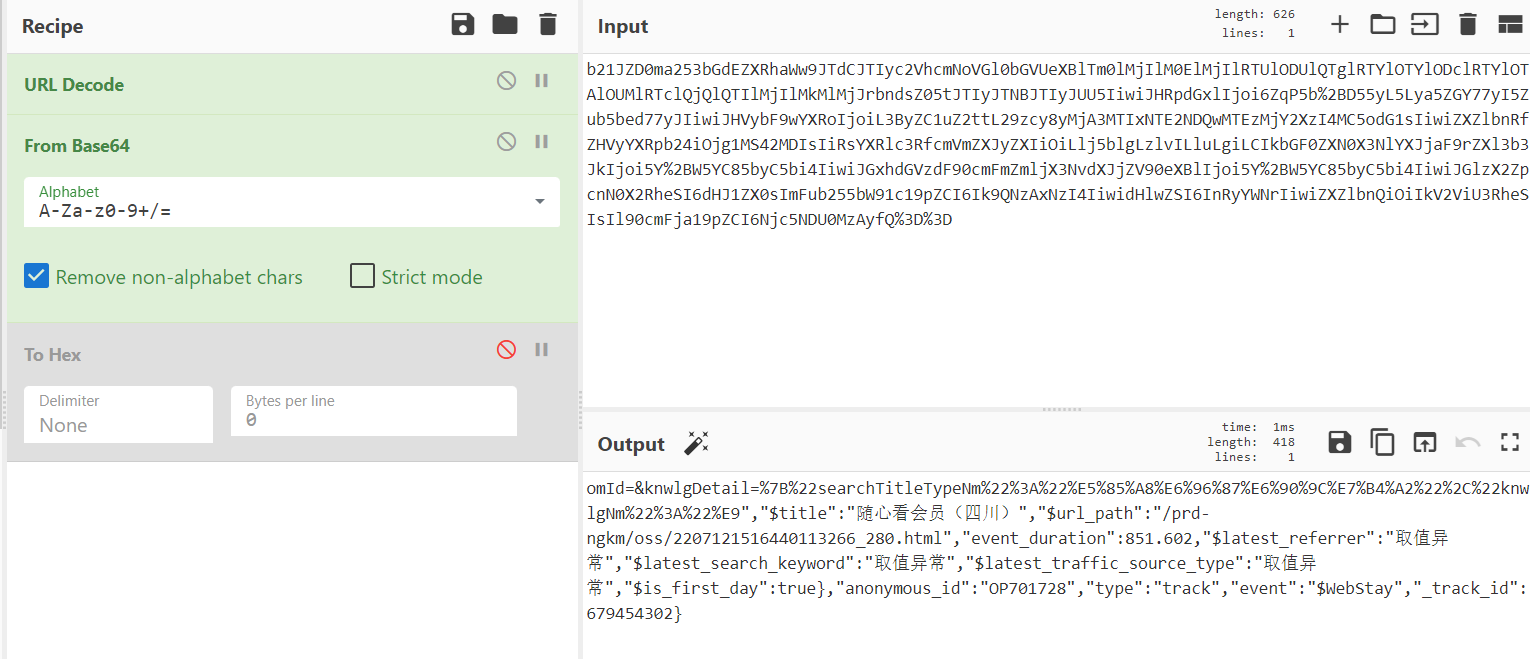
后续一直追问ai问什么要去掉,他也解释不出来,就是莫名奇妙url解码后,最前的0就没有了;
与此同事一个同事也解出来了,没有使用ai,他说base64的首位不可能是0,他没见过0开头的base64编码;
于是故事就开始了:
0x02 分析思考
一、Base64的首位难道是有什么规律吗?
我们都知道base64就是一个编码,其旨在把所有的信息编码成可见字符的形式存在,从而方便传输和使用;
其原理也比较简单,就是把8位一个的0/1进制转化成6位一个的0/1进程,也就是说原来的三个字节(一个字节等于8位),base64编码之后变成了四个字节;
几个例子
A 对应的ascii 是 0x41 , 把这两位16进制分解成2进制,第一位4变成:0100;第二位1变成 0001;
如果我们把A变成base64编码,其实就是只要前六位二进制的内容, 0100 00 转化成十进制就是:16;
base64里面的编码字符一共64个,rfc标准版是由【A-Z a-z 0-9+/= 】组成的,编码顺序就是括号里面的排序,16就是第17位,A-Z里面的第17位就是:Q,所以只要是以大写的A开头的内容,其base64编码后都会是Q开头;
比如:
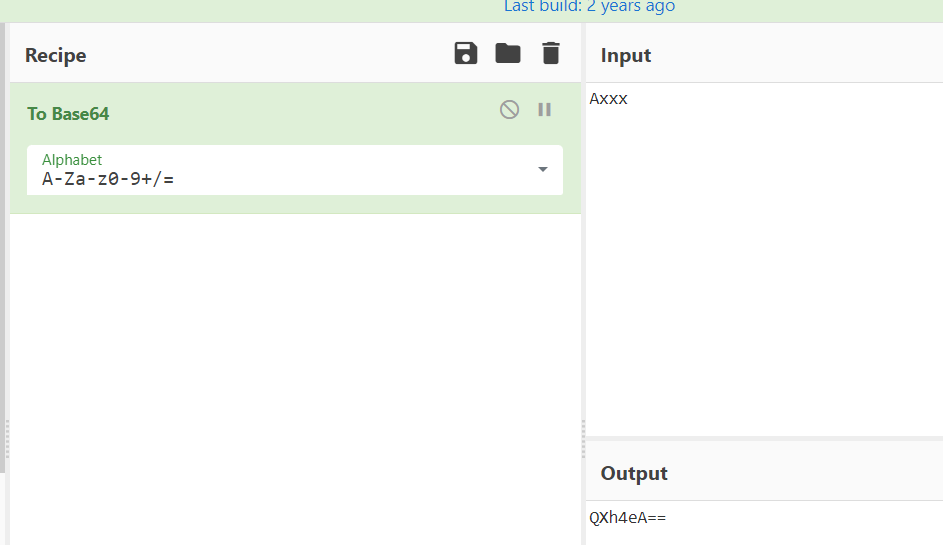
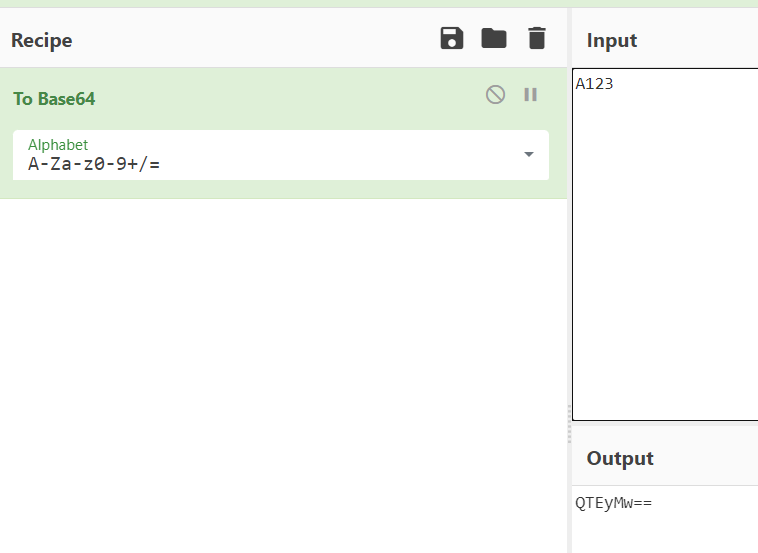
都是如此,那么我们顺着上面0开头来说,反着推下0开头是个什么情况:
0 在 标准base64编码里面的按顺序排是 第53位(前面有大小写英文字母各26个),那就是编号52,52转化成2进程:32+16+4:1101 00,这里是6位2进制数字,反着变回去的时候需要变成8位,后面可以随意的填写两位,存在以下几种可能:
1
2
3
4
1101 0000
1101 0001
1101 0010
1101 0011
分别转换回16进制的时候:
1
2
3
4
d0
d1
d2
d3
也就是说:只要是转化成16进制是以d0-d3开头的字符,其就能使base64编码的首位变成0:
我们直接拿d0举例,如下,先通过from hex 找到 转化16进制之后为d0的字符,然后对其进程base64编码,我们拿到了0开头的base64编码:
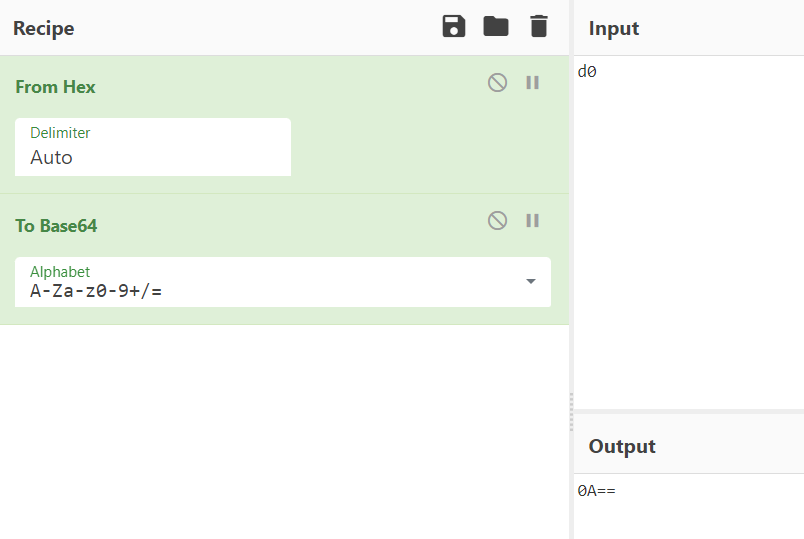
只要是转化成16进制是以d0-d3开头的字符,其就能使base64编码的首位变成0;
至此上面这个问题就解决了;
此时那个同事说,d0不是可见字符,所以我们按照常规的推理,会先排除;
其实他这个话就是说:以可见字符开头的内容其base64编码首位不可能是0;
二、以可见字符开头的内容其base64编码首位不可能是0?
乍一听,好像有道理奥,哈哈哈(其实这里这个问题就不再是,base64能不能以0开始了,而是base64开头真的有限制吗,如果我们对待编码的内容开头进行限制,base64开头会有一些奇特的规律,还是比较值得细细看下的)
其实不然,这里我们注意上面得出来的结论:《只要是转化成16进制是以d0-d3开头的字符,其就能使base64编码的首位变成0;》,我们下意识的觉得所有的字符都是单字节的编码了,其实不然;
我们拿unicode举例,其号称万国码,UTF-8使我们最常见的unicode编码之一,其存在形式如下:
UTF-8原则:
- 对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。因此,对于英文中的 0 - 127 号字符,与 ASCII 码完全相同。这意味着 ASCII 码那个年代的文档用 UTF-8 编码打开完全没有问题。
- 对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N - 1 个字节的前两位都设位 10,剩下的二进制位则使用这个字符的 Unicode 码点来填充。
编码规则如下:
| Unicode 十六进制码点范围 | UTF-8 二进制 |
|---|---|
| 0000 0000 - 0000 007F | 0xxxxxxx |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
我们回到base64之后的开头的0来看,其转换十进制之后为52,转化二进制并补齐八位之后为1101 00xx ,里面的x都是可以随便置值的,当为双字节编码的内容的时候,第一个字节是d0-d3(上文计算过),双字节就是d0xx d1xx d2xx d3xx,我们可以看到这个落到上面的unicode的表示范围里面的时候,其实是落到三字节编码里面了0800-FFFF之间,所以UTF-8编码里面我们是找不到base64编码结果是以0开头的字符了;
UTF-8不行那就gbk:
GBK原则:
GBK 采用双字节表示,总体编码范围为 8140-FEFE 之间,首字节在 81-FE 之间,尾字节在 40-FE 之间,不再规定低位字节大于 127,剔除 XX7F 一条线。
正好GBK就是我们想要的双字节编码,并且上面我们计算的d(0-3)xx也是在 规定的8140-FEFE之间的;
查阅编码表随便找一个合适的:比如:《新》这个汉字,gbk编码是《d0c2》:

这里我们对d0c2的进行base64编码:
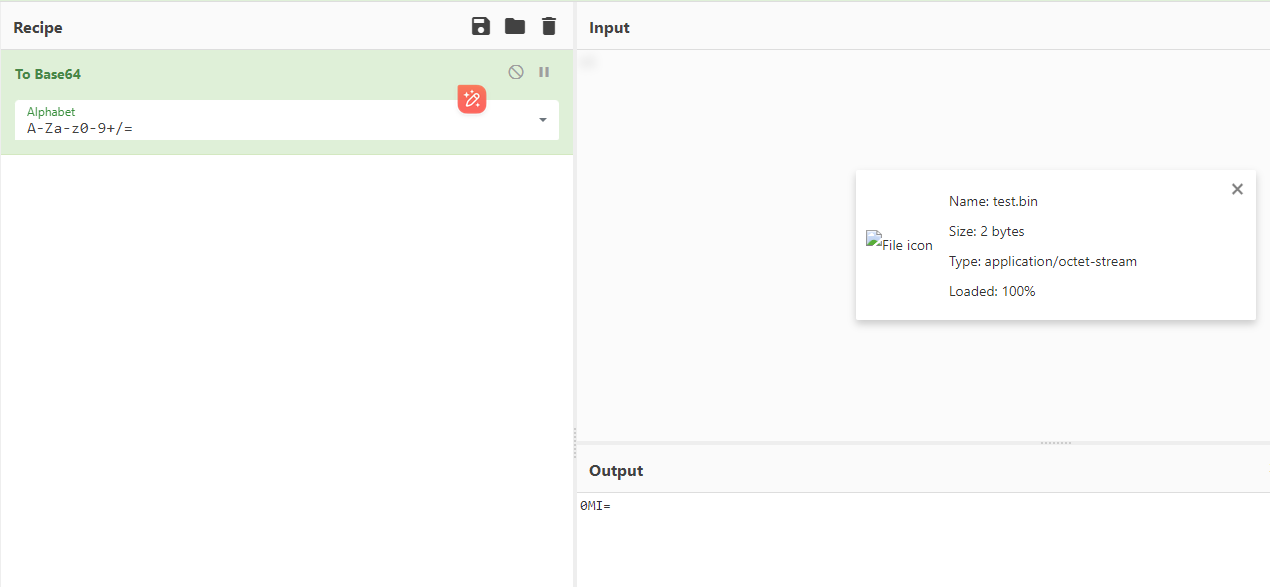
创建一个test.bin
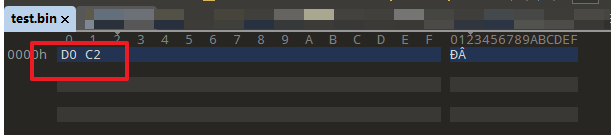
编码结果是:0MI=
使用gbk解码,如下图,就是我们的新:
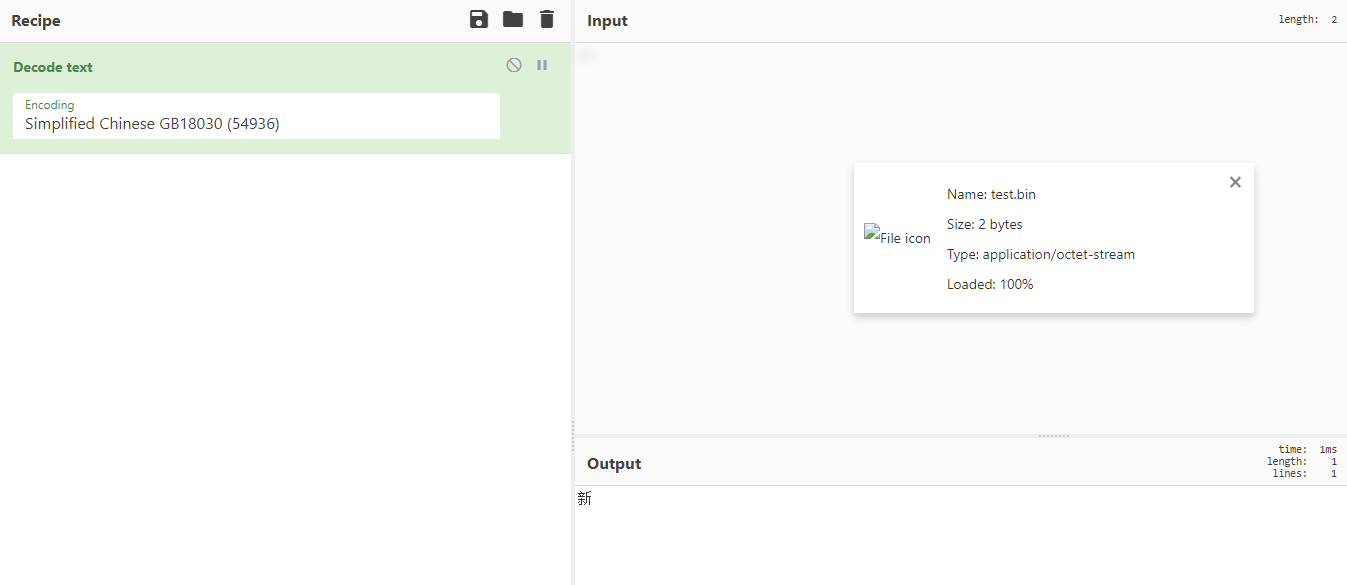
所以峰回路转这里我们的确能得出个结论:
在gbk编码中,以可见字符开头的内容其base64编码的值的首位可能会是0,比如:新;
所以这里上面那句话需要加一个条件才成立:
在unicode编码中,以可见字符开头的内容其base64编码的值的首位不可能会是0;
那么拉回我们对al的讨论,为什么gpt能够自动去除第一位0呢?
三、gpt怎么做到智能解码的被冗余混淆的base64编码结果的?
通过测试 openai的GPT-4o,发现我发现,其实这个里面是没有agent概念的,都是推理,通过学习过的资料推理来做的解码,也就是说他或多或少接触的资料里面有编码和对应解码的内容,学习了这之间的映射关系。
为什么会这么说呢,我这里有个例子:
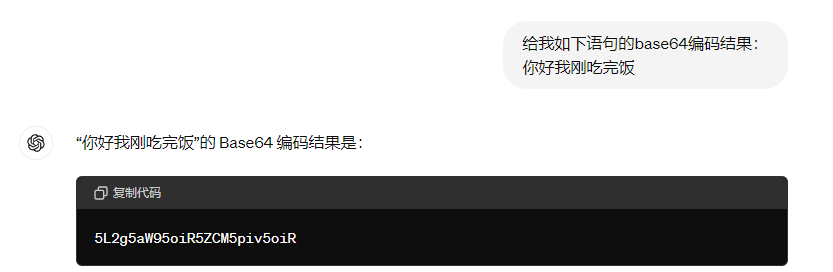
将拿到的答案,解码处理,如下图,我们可以看到是错的,这就是因为他没有通过agent形式去做处理,纯靠自己推理,没有置入“硬逻辑”。
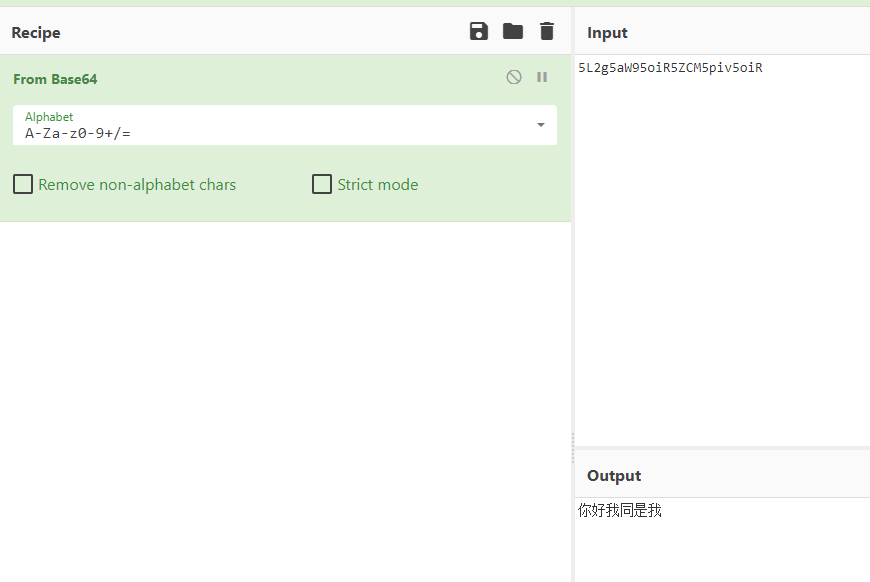
那么al为什么可以解出来我们的那个冗余base64编码内容里面的部分结构和内容,就很好解释了,他才不管你放到哪里,就是看一点对一点,0b21 可以是一个单元,b21J也可以是一个单元,去从他之前学习的材料里面推理;所以他能将部分结构推理出来,并且有些英文可以还原,但是中文还原不了,我估计是中文学习材料太少导致的。
0x03 总结
随笔记录下一个编码的小问题的,之前也没关注过所谓的首位问题,这里简单的分析了下,之后或许对提升个人的数据敏感度能够有帮助;
同时我们也不难看出,其实对于大模型来说,通过内置agent形式实现一些具体场景的大模型是一个趋势,agent的结果就是推理模型输入的一部分;